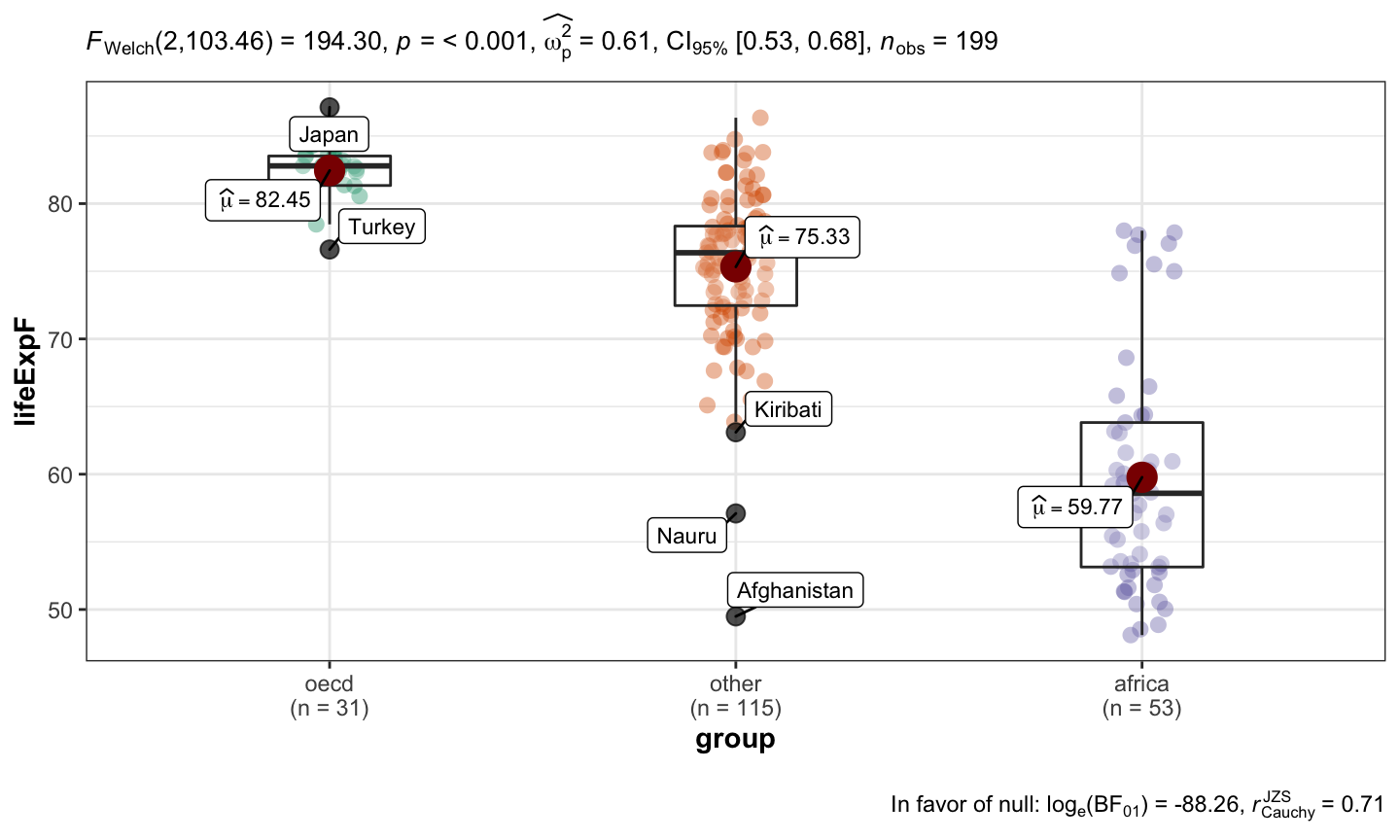
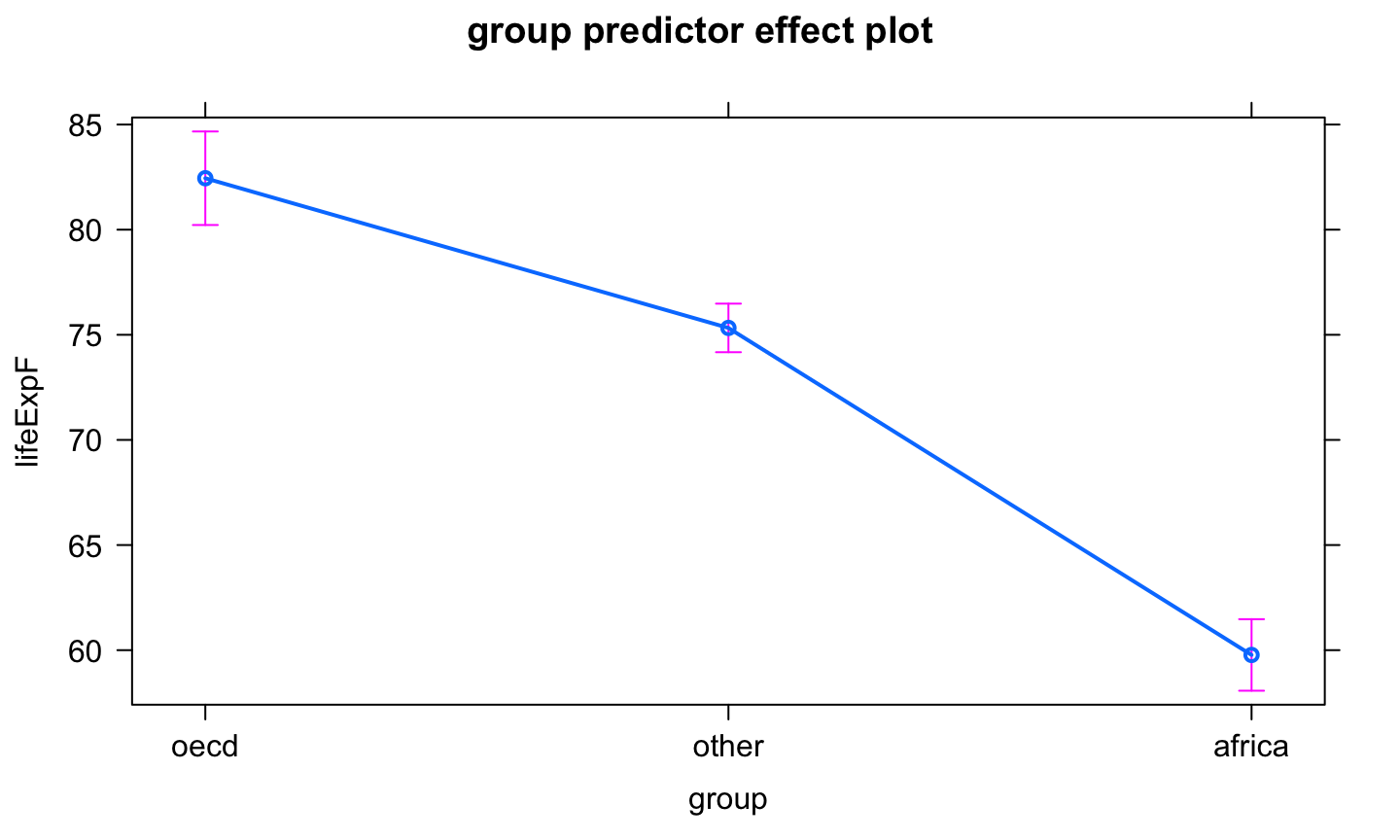
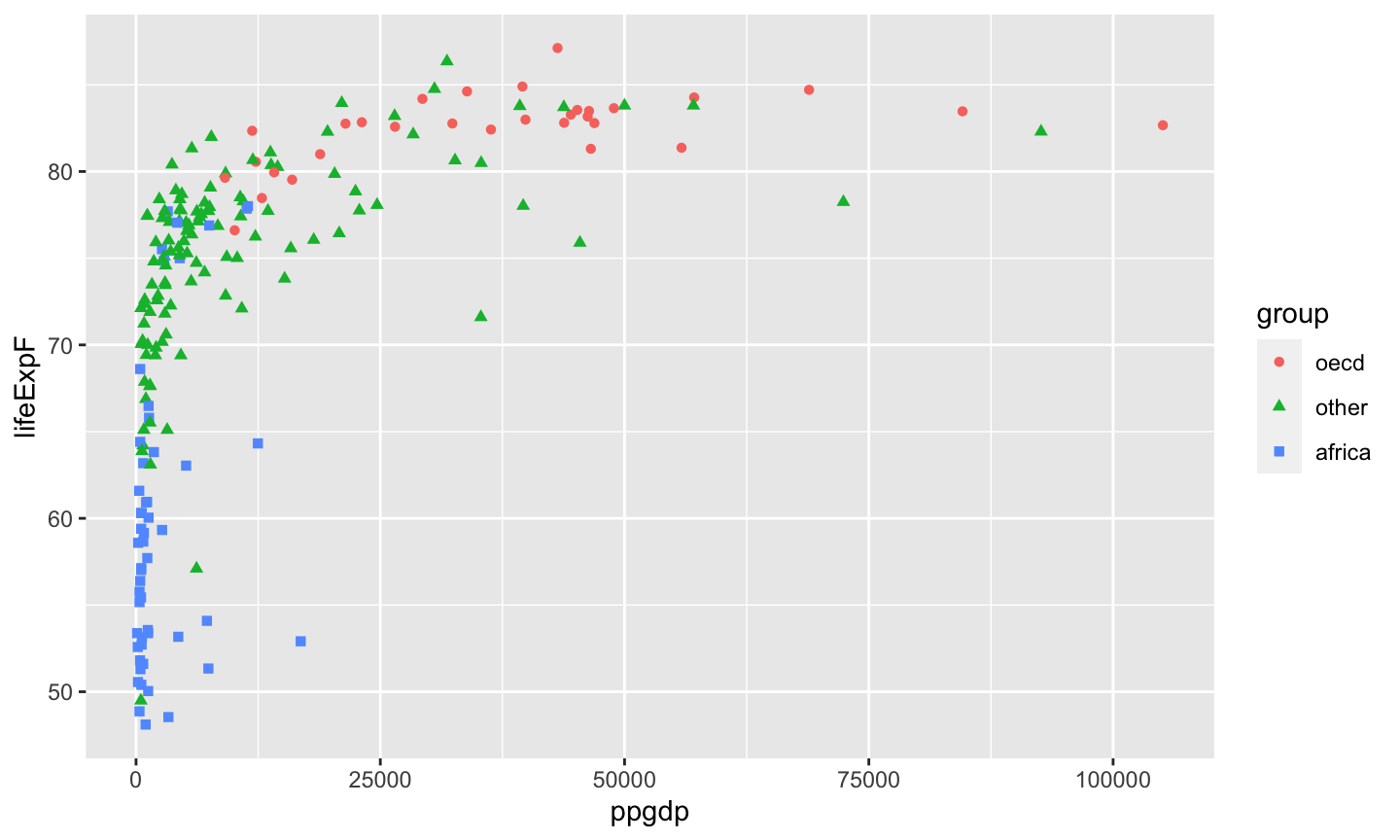
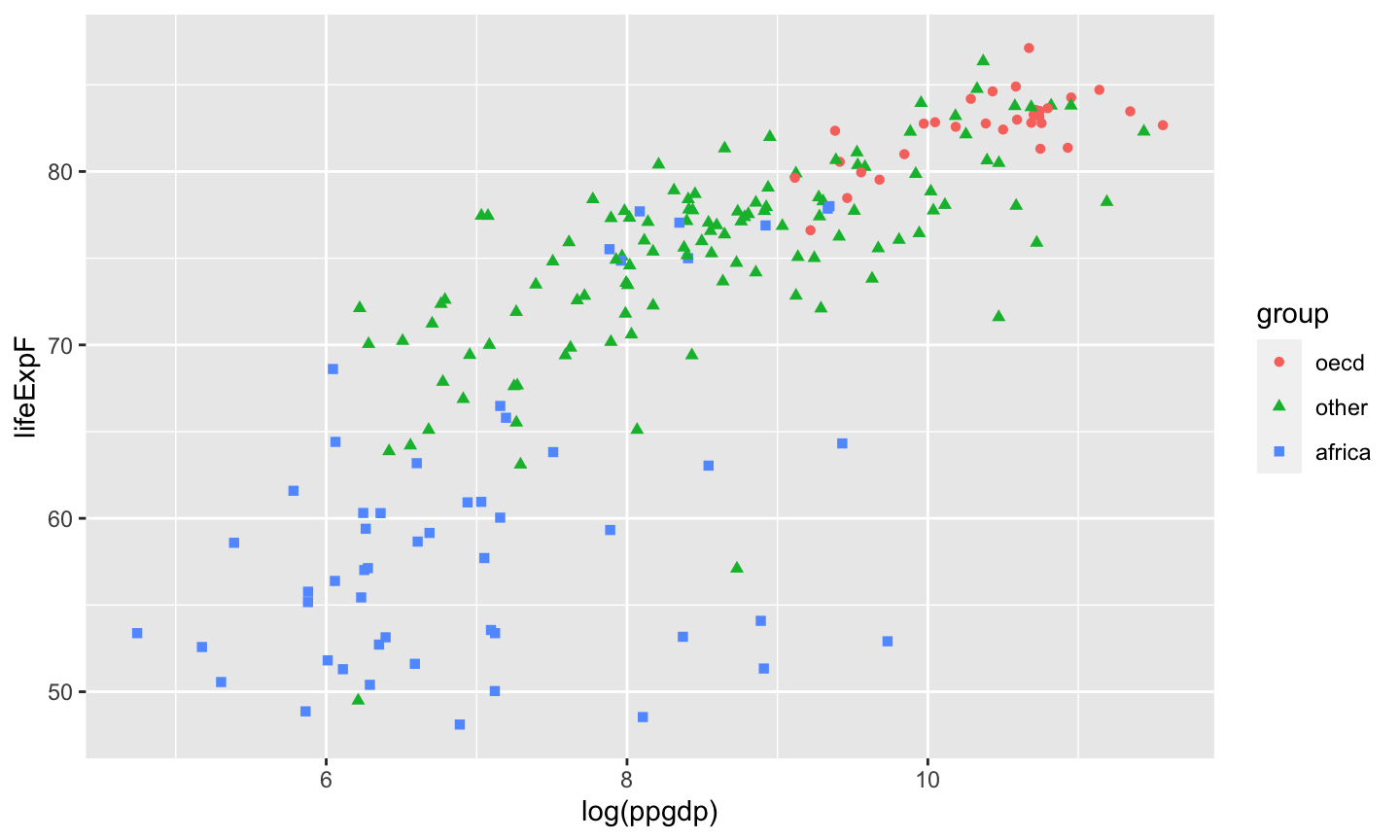
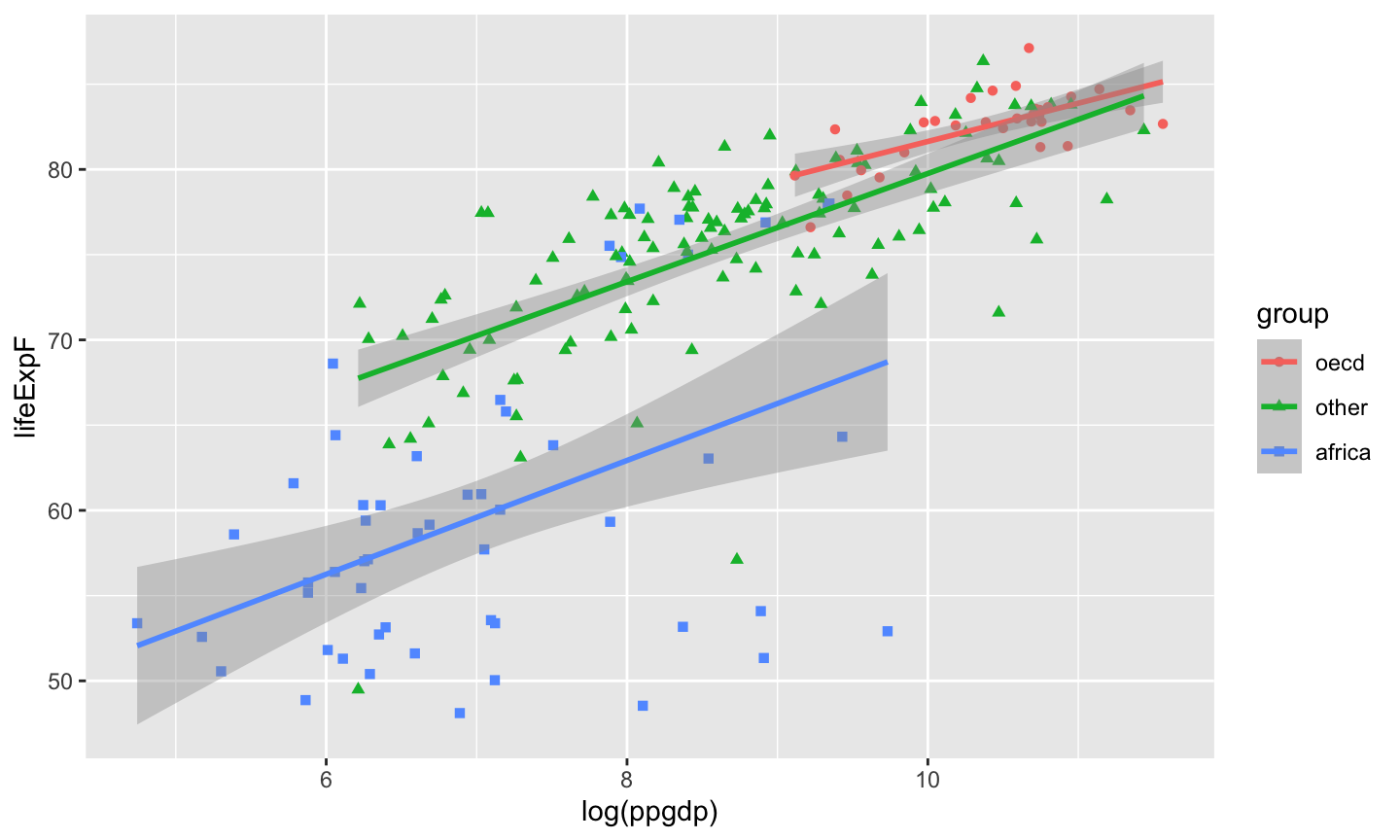
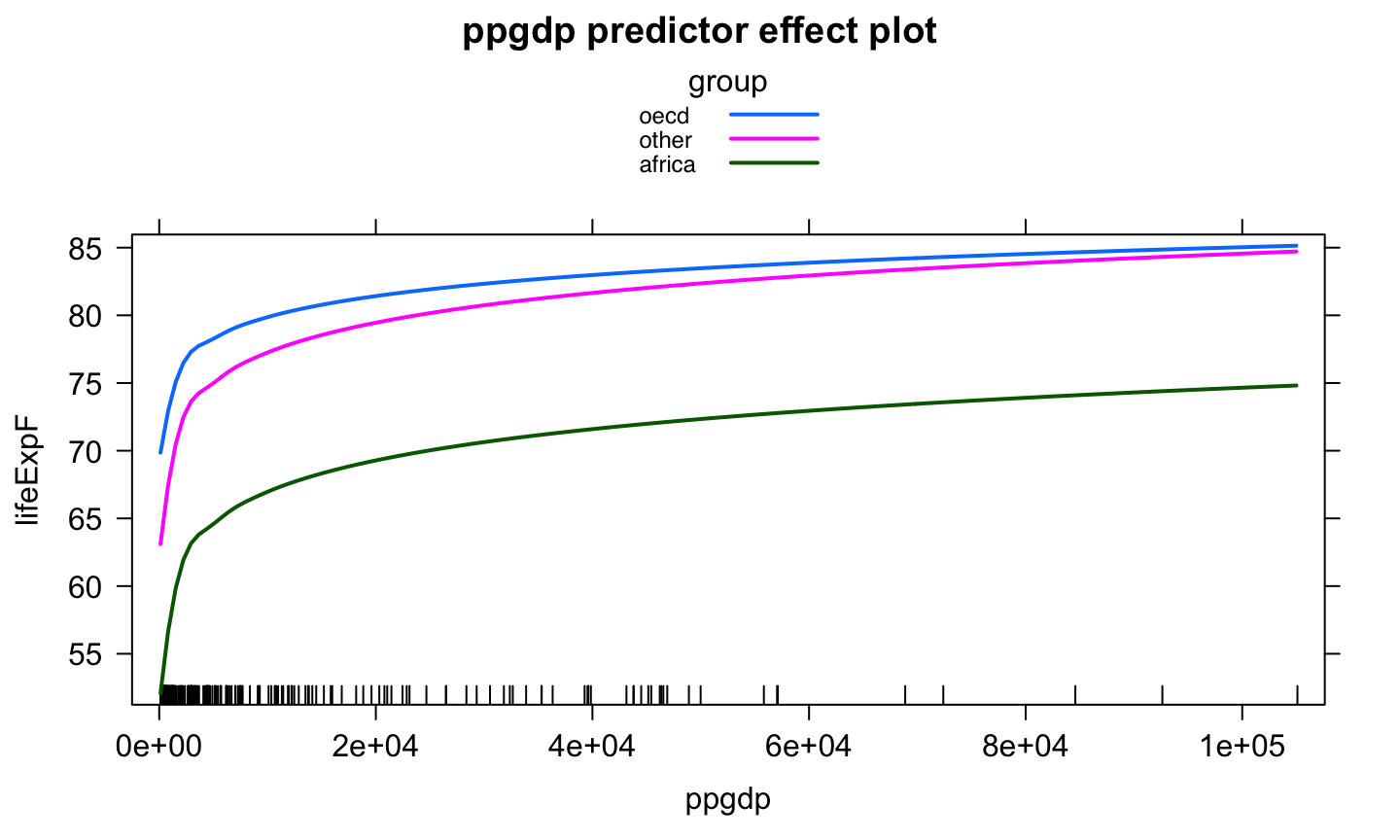
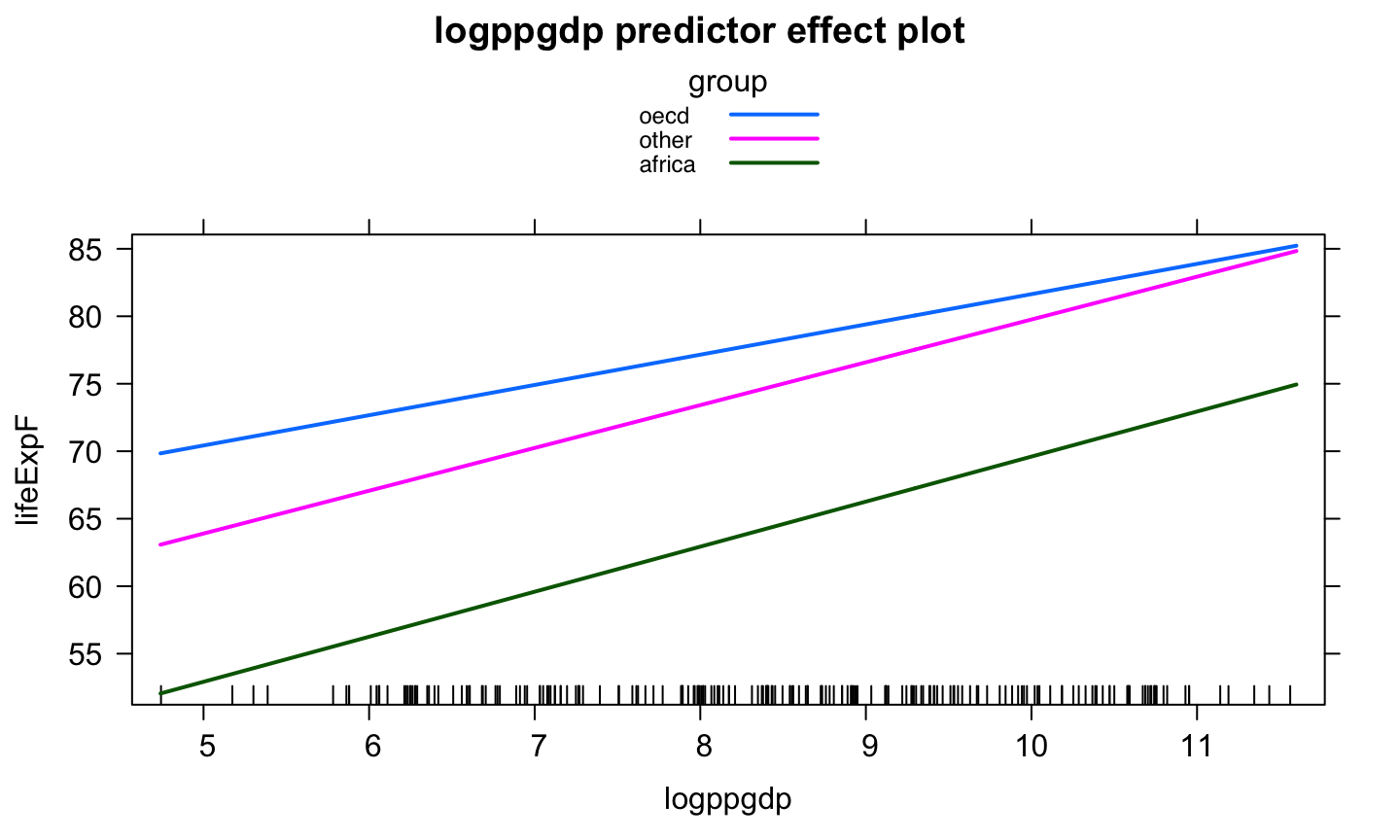
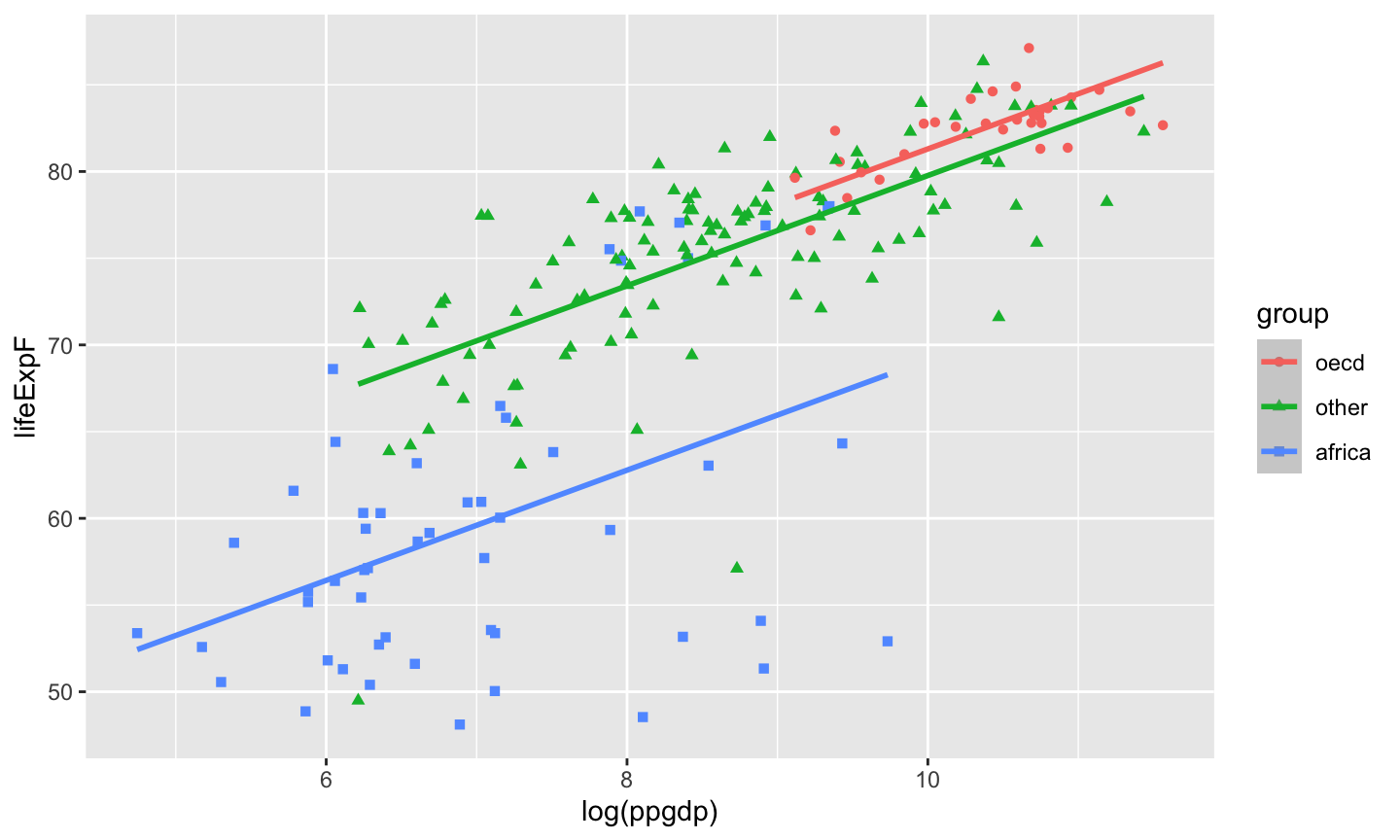
A categorical variable is a variable that can take on one of a limited, usually fixed, number of possible values, assigning each individual or other unit of observation to a particular group or nominal category on the basis of some qualitative property.
Categorical predictors are often called factors