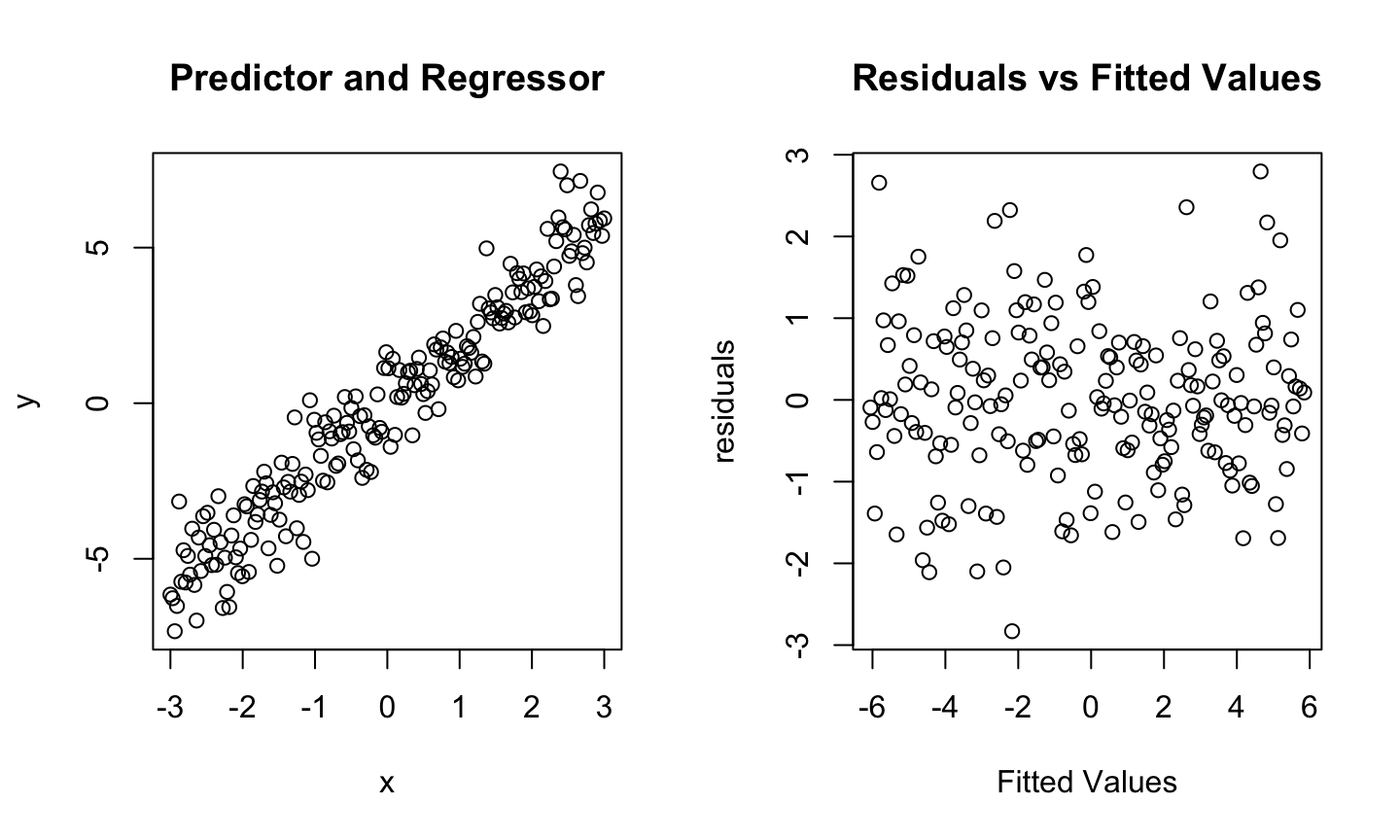
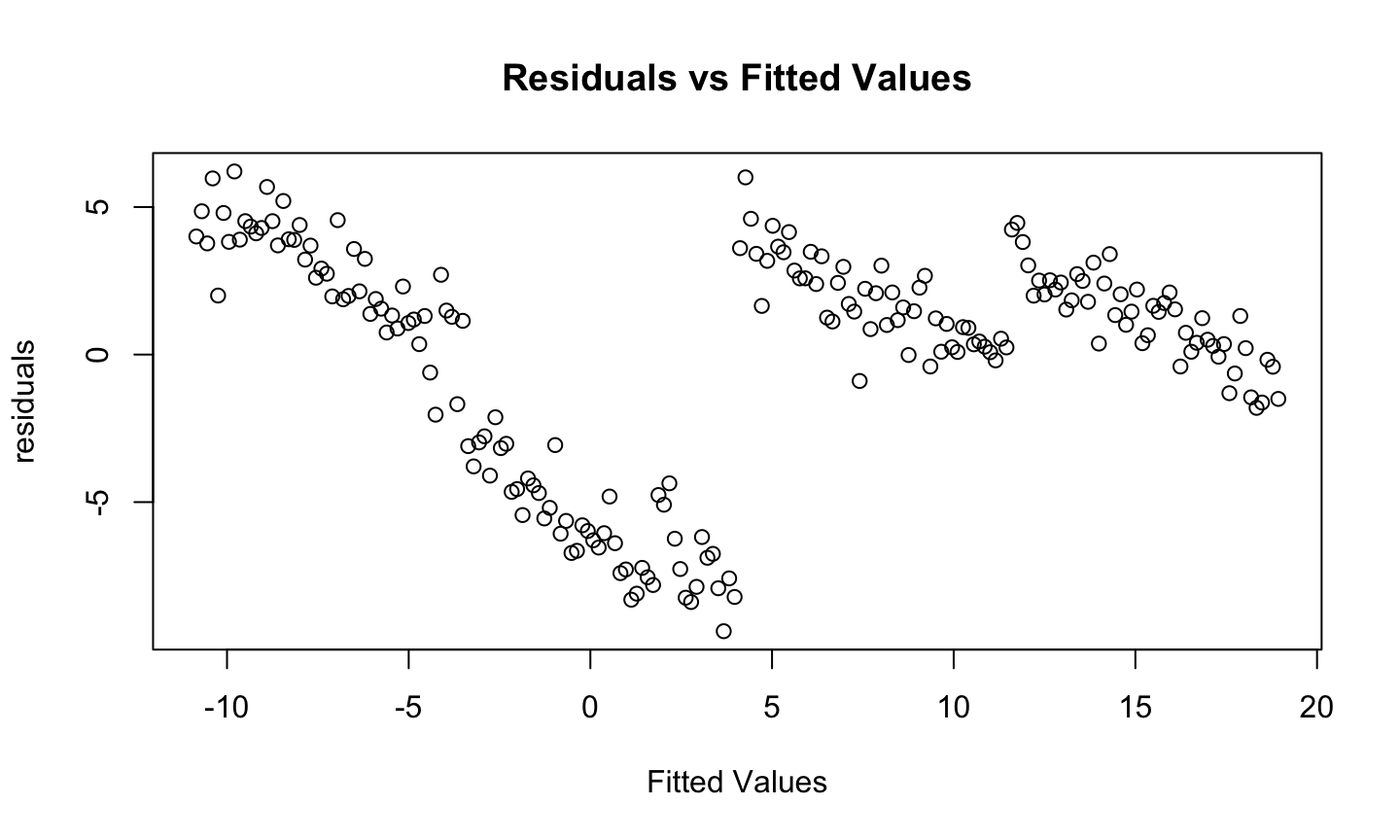
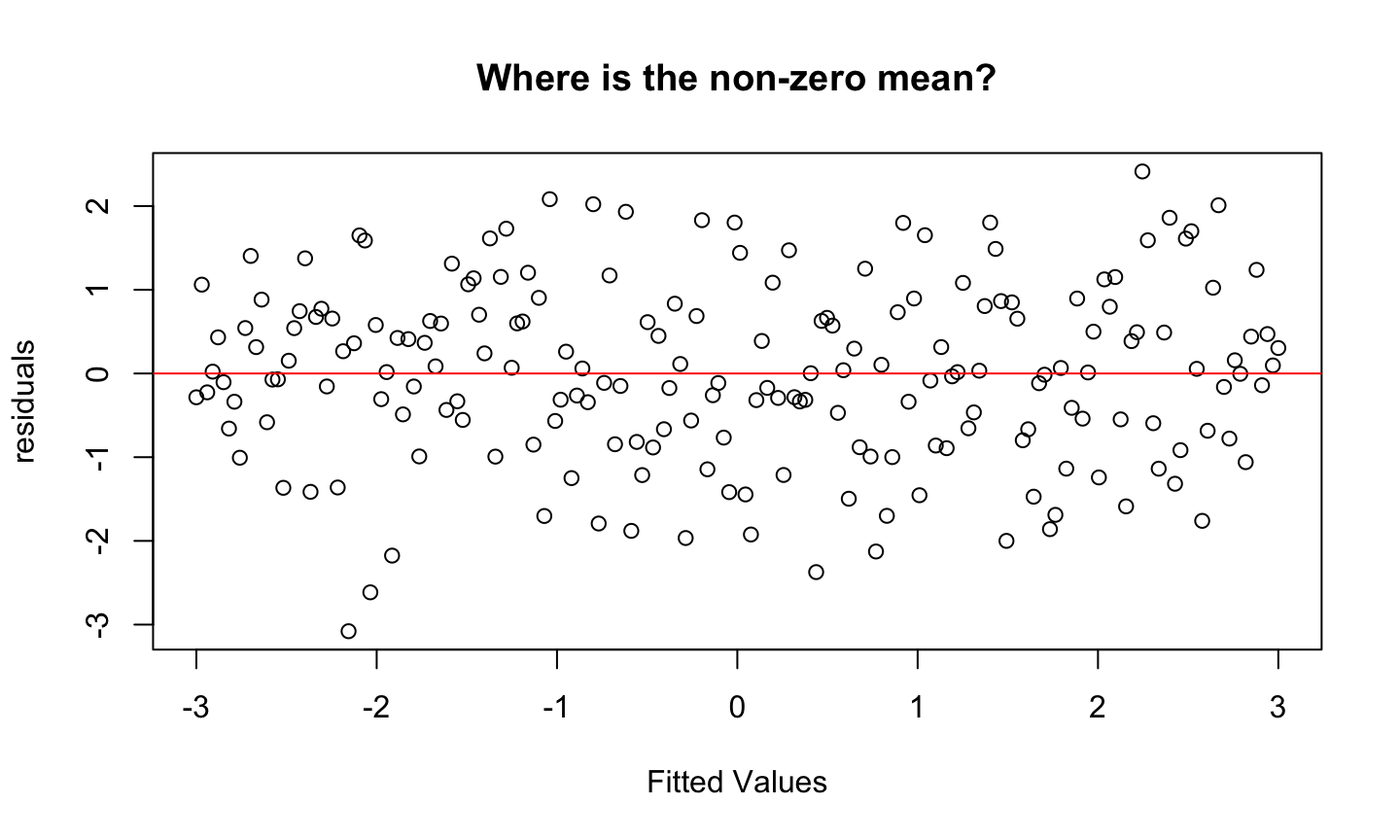
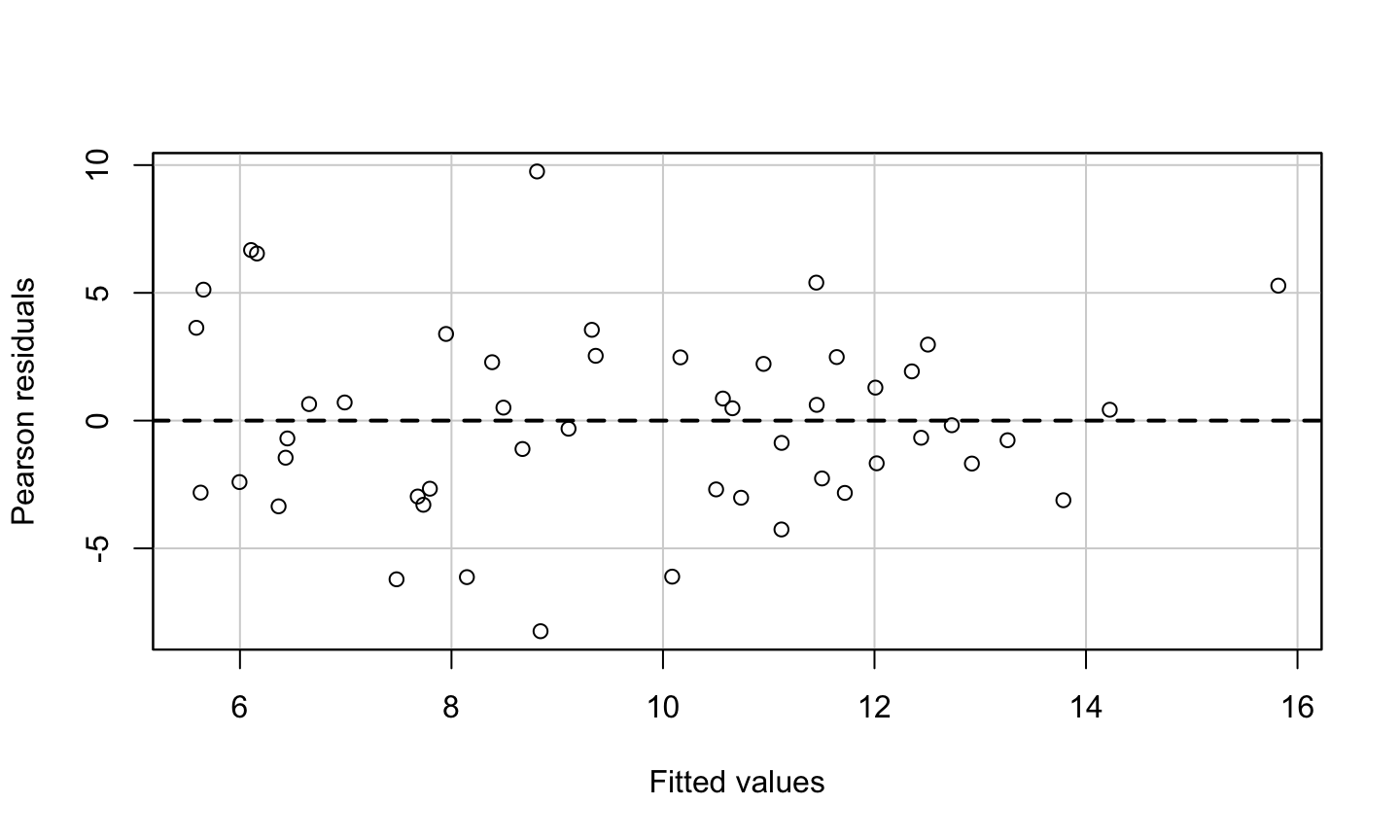
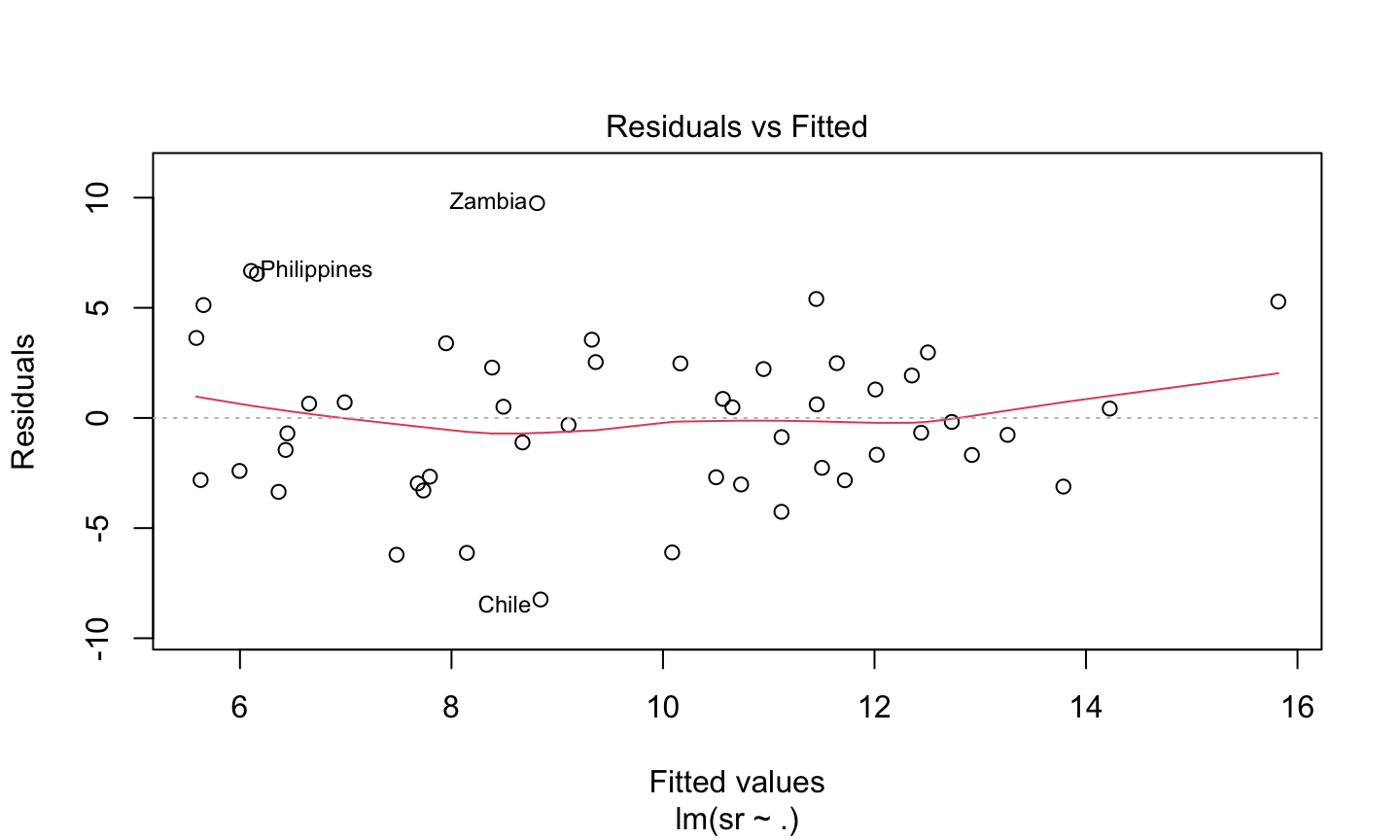
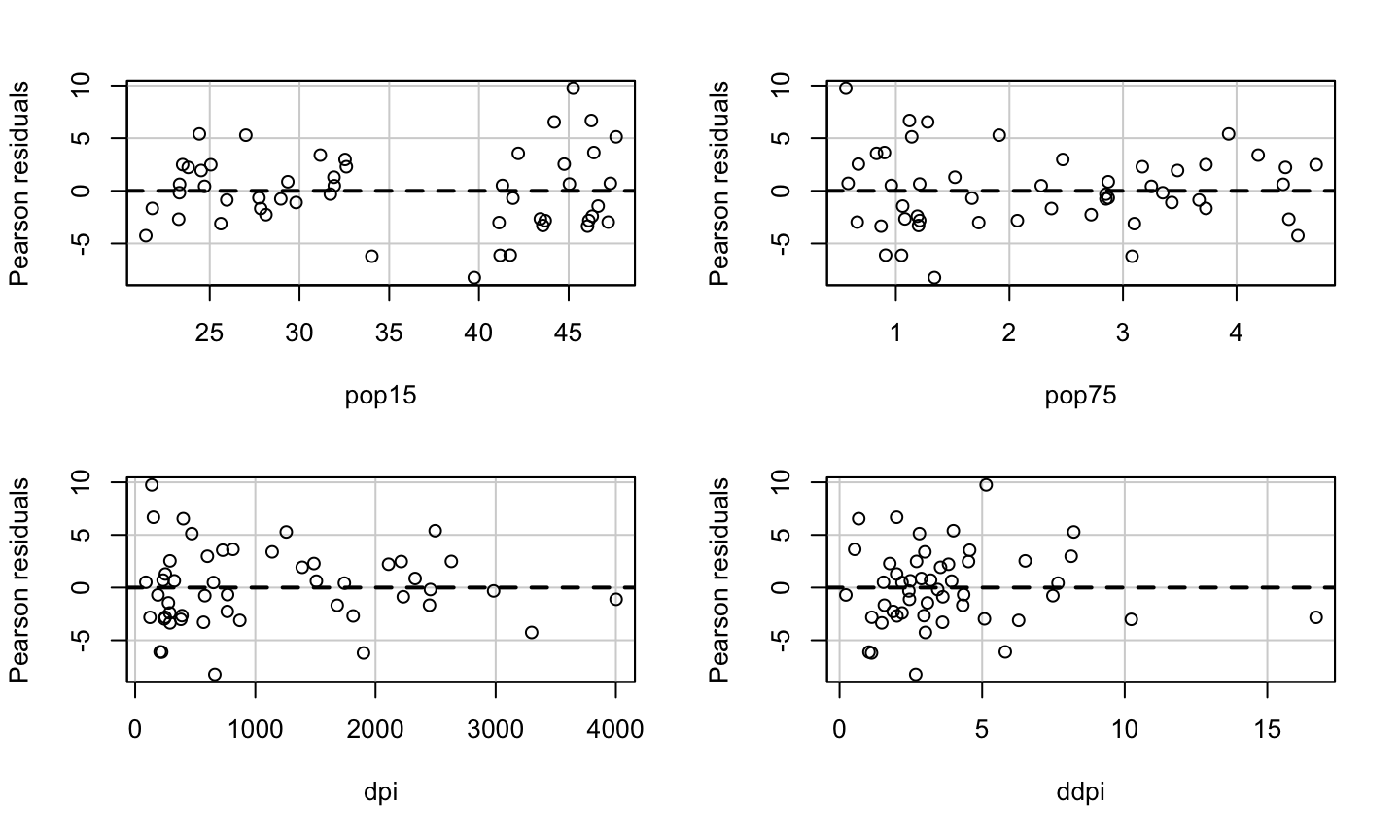
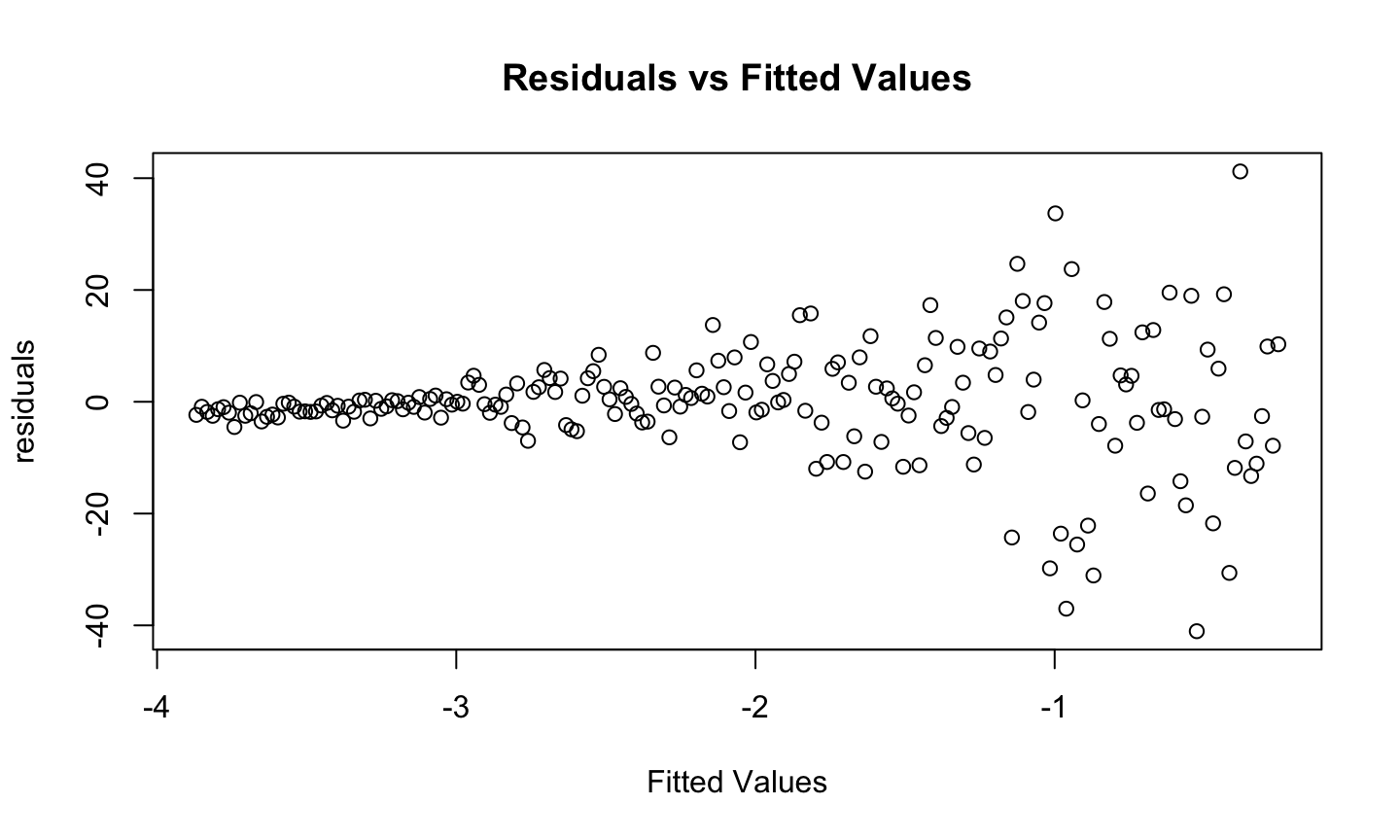
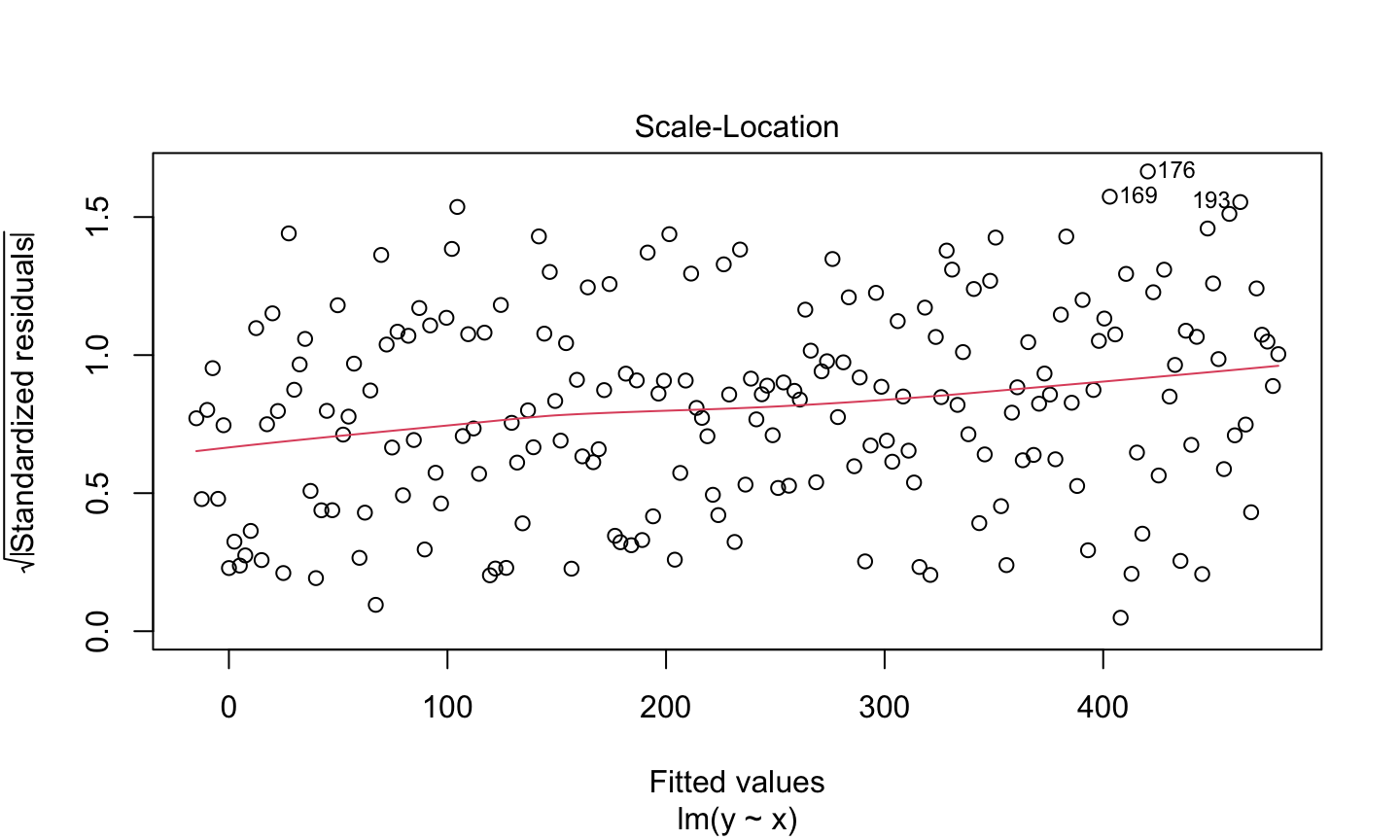
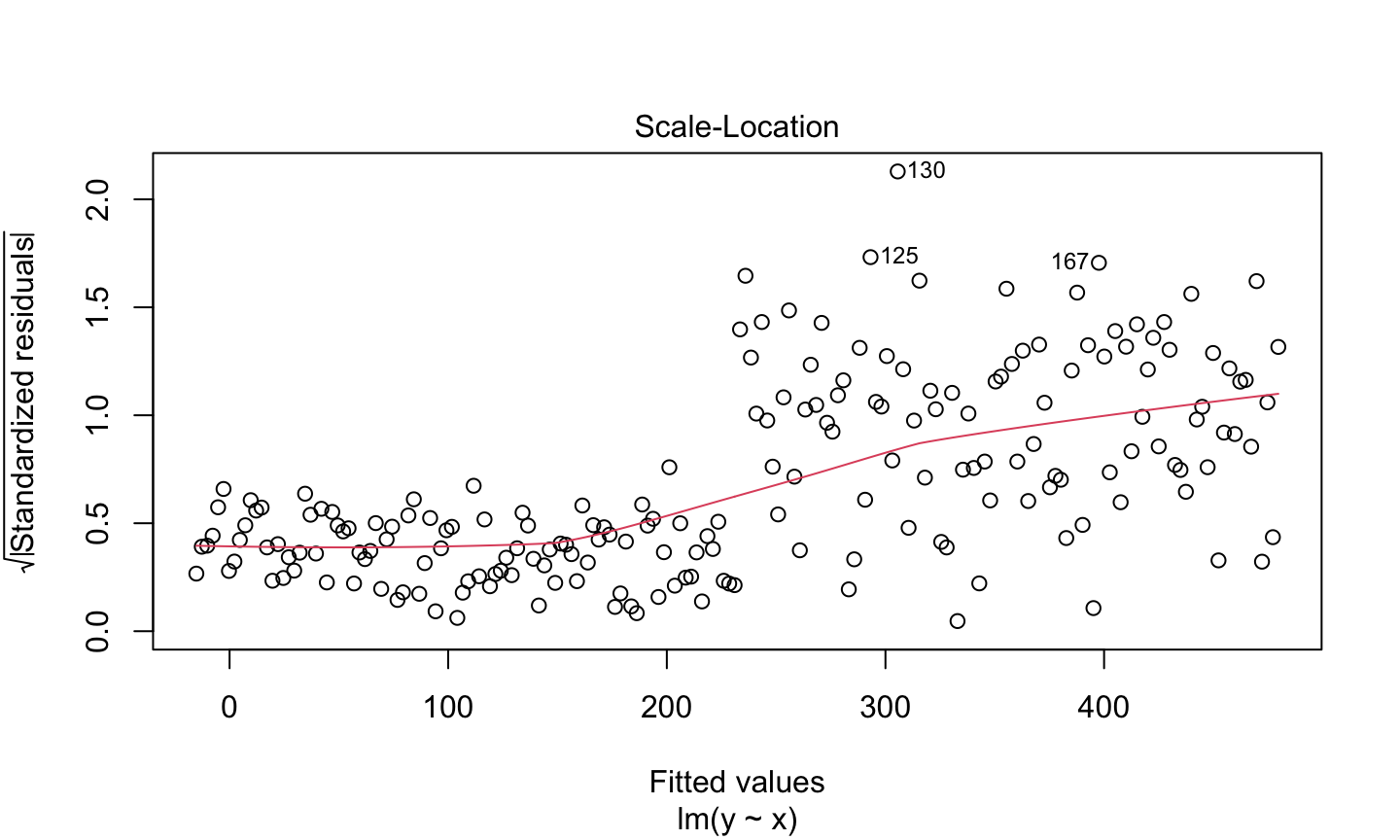
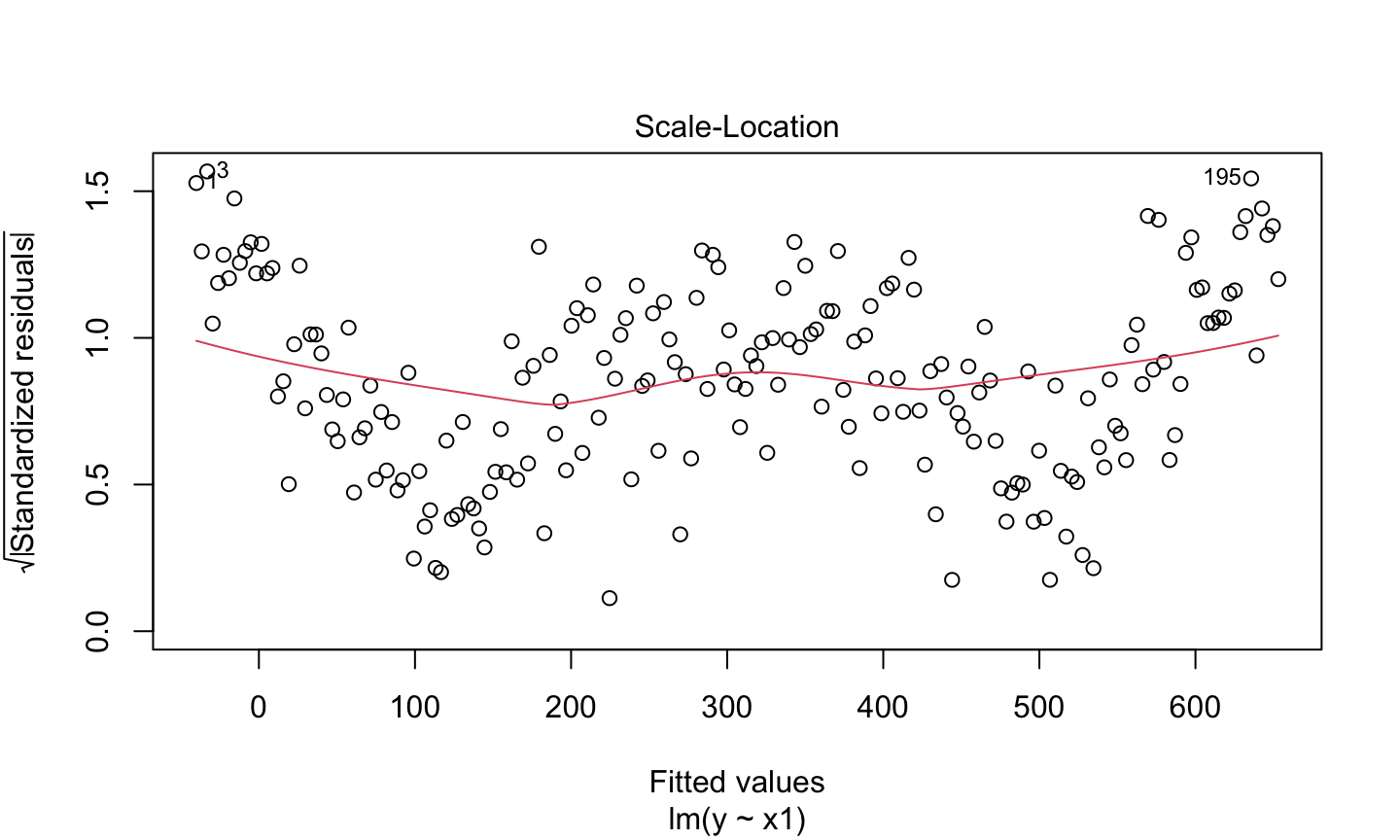
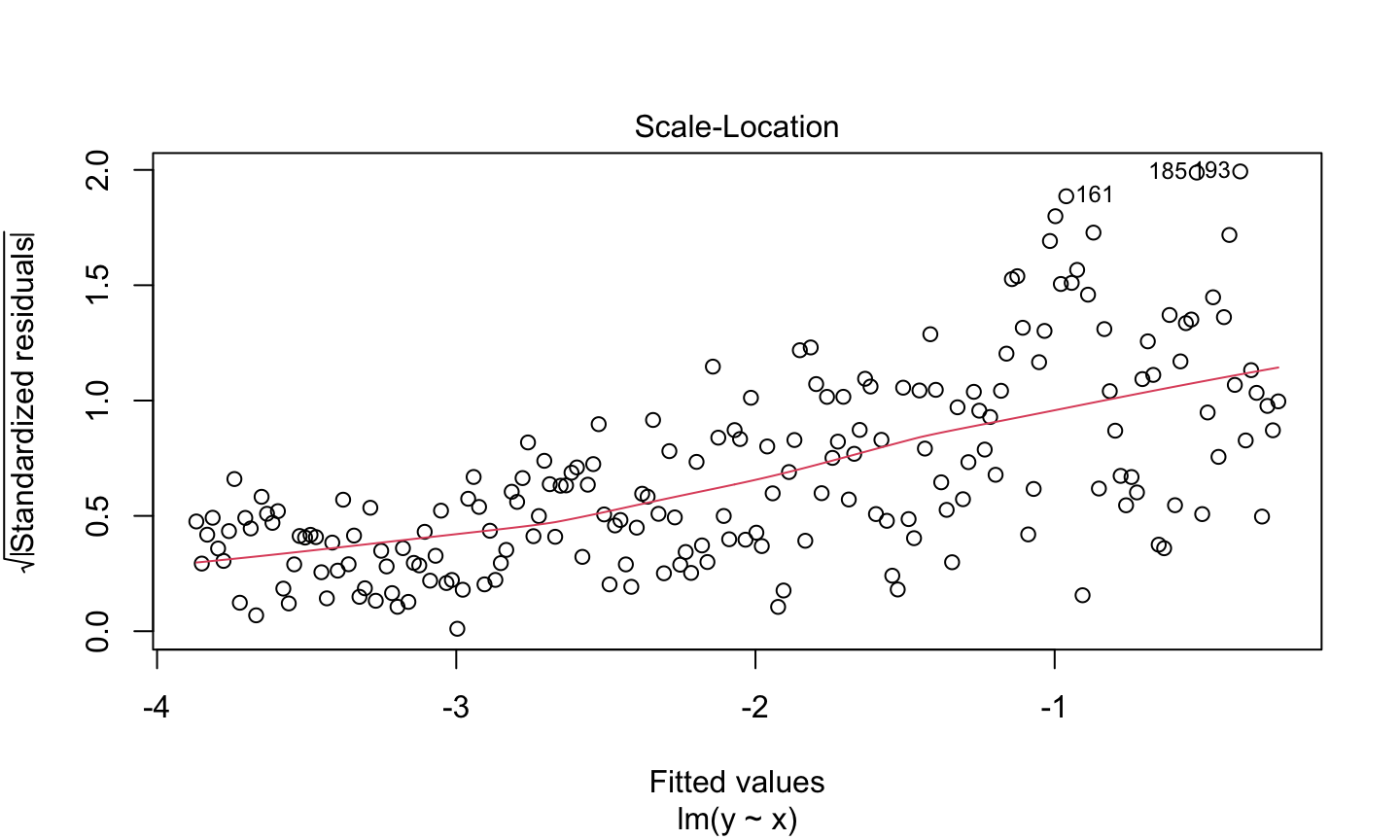
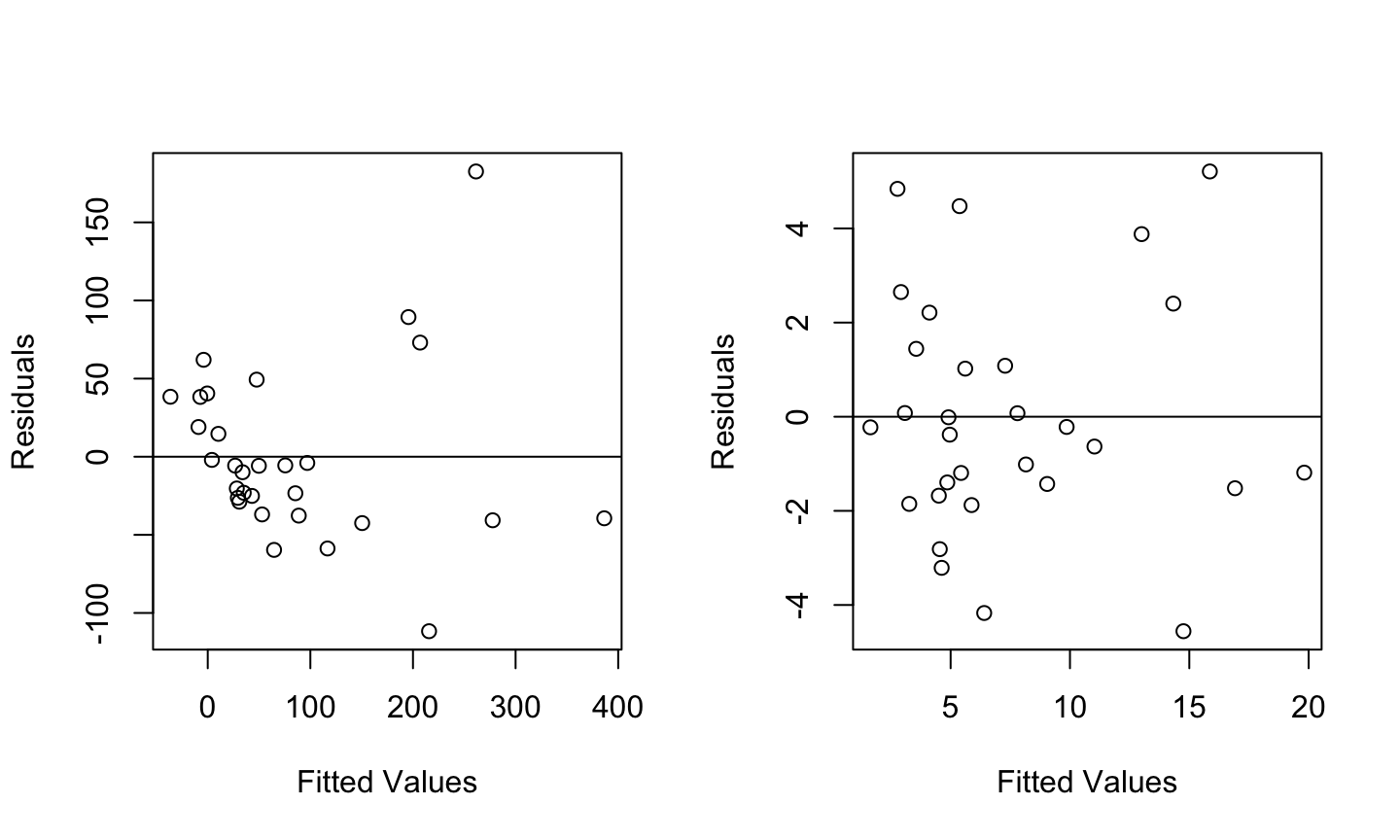
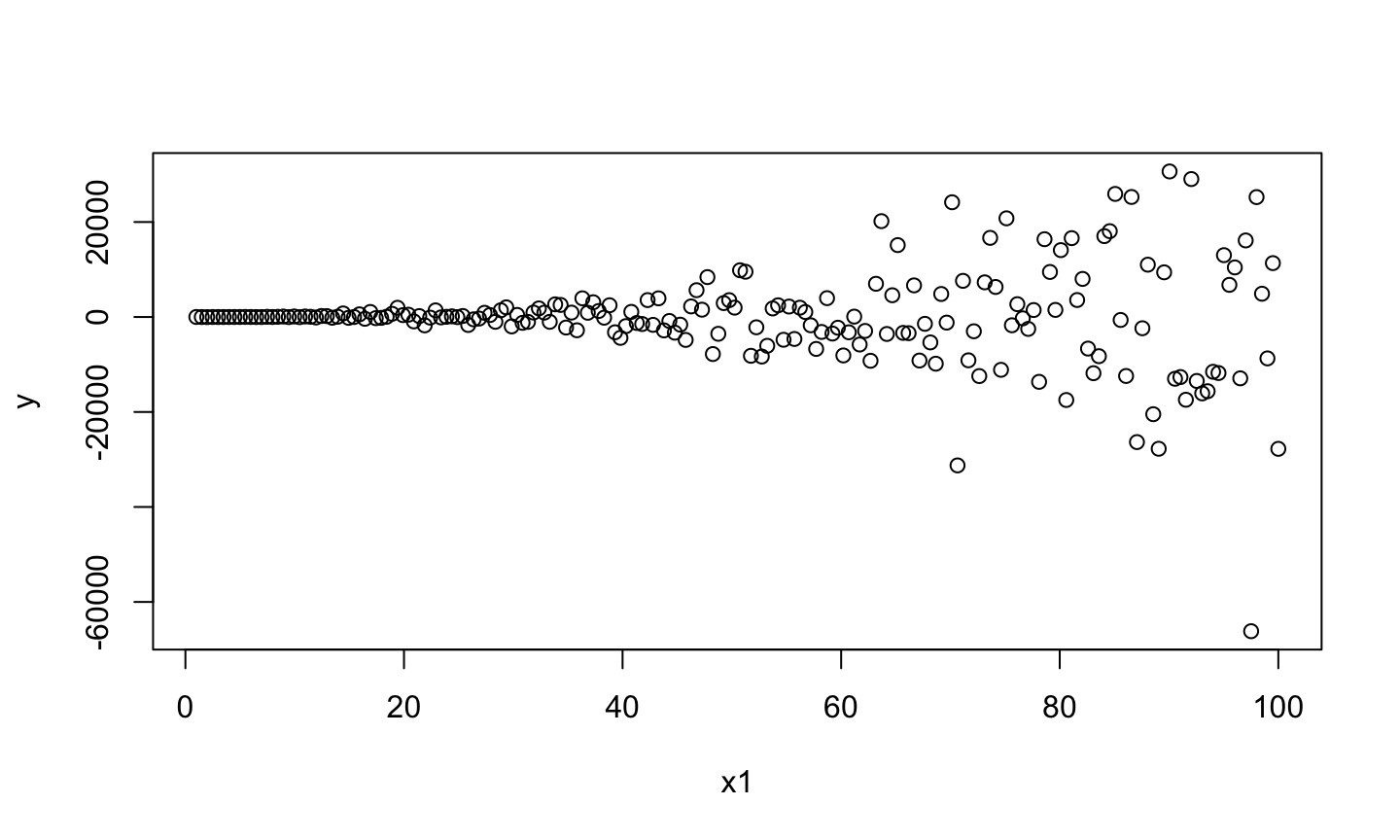
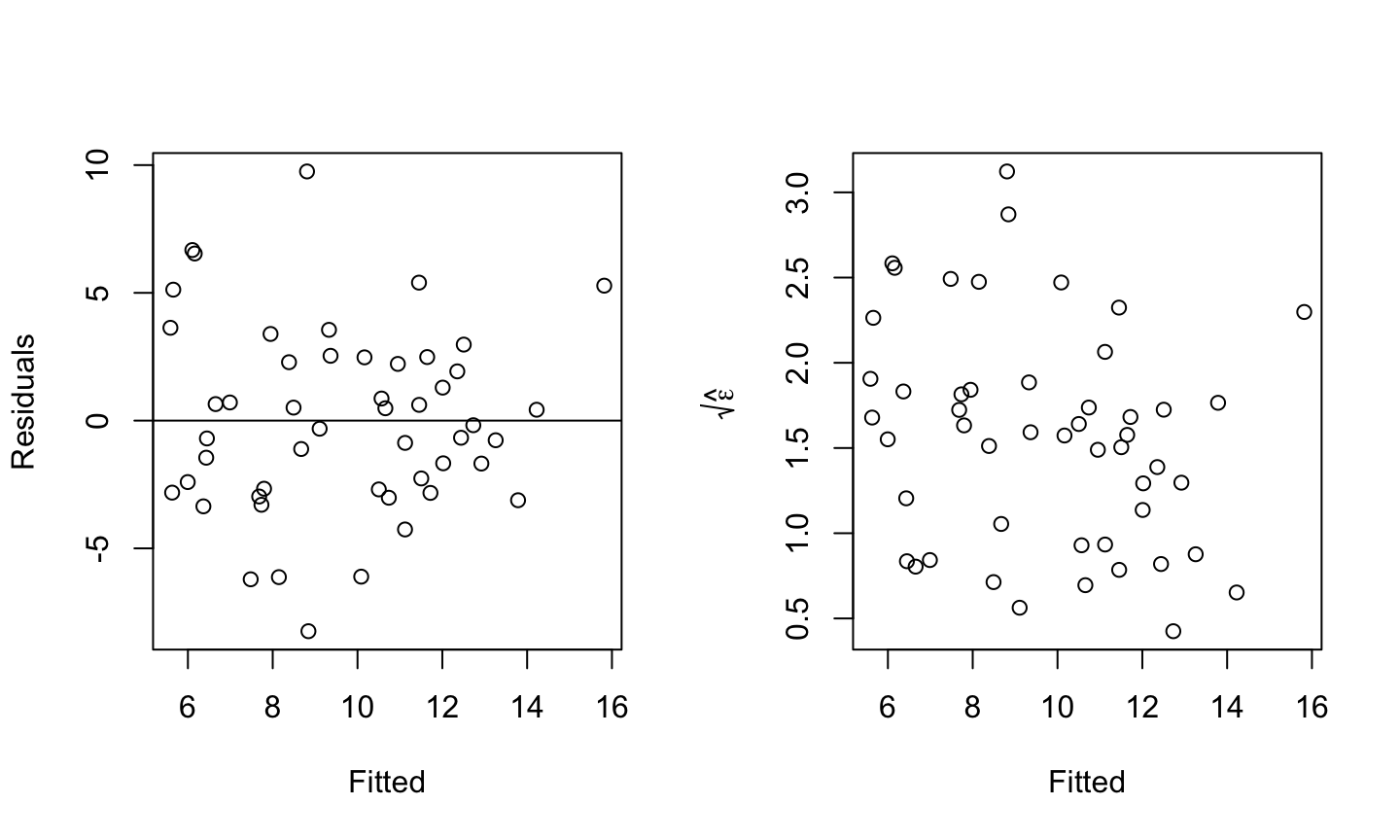
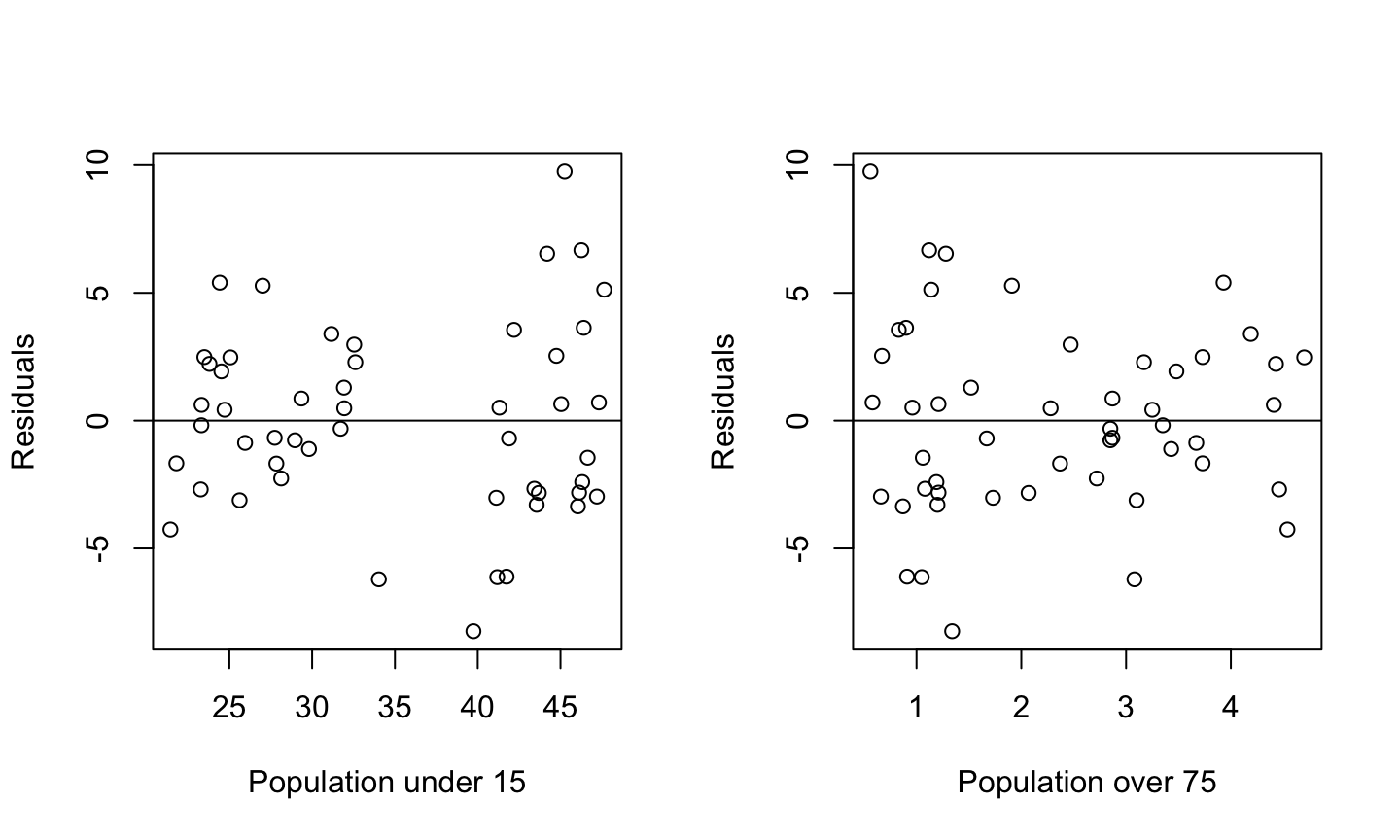
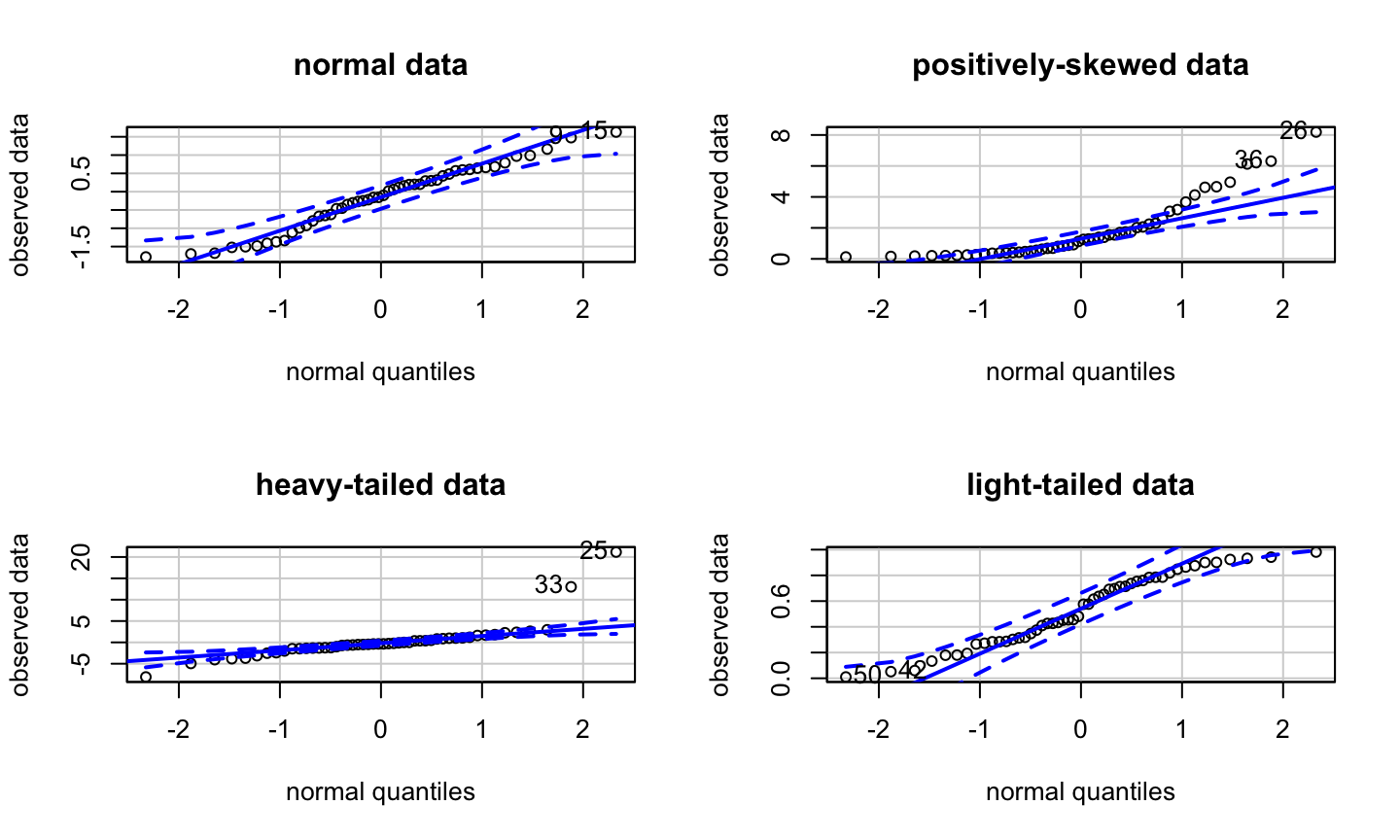
Estimation and inference for a regression model depend on several assumptions. The three main categories of assumptions are:
Model: The structural (mean) part of the model is correct, i.e., \(E(y)=X\beta\).
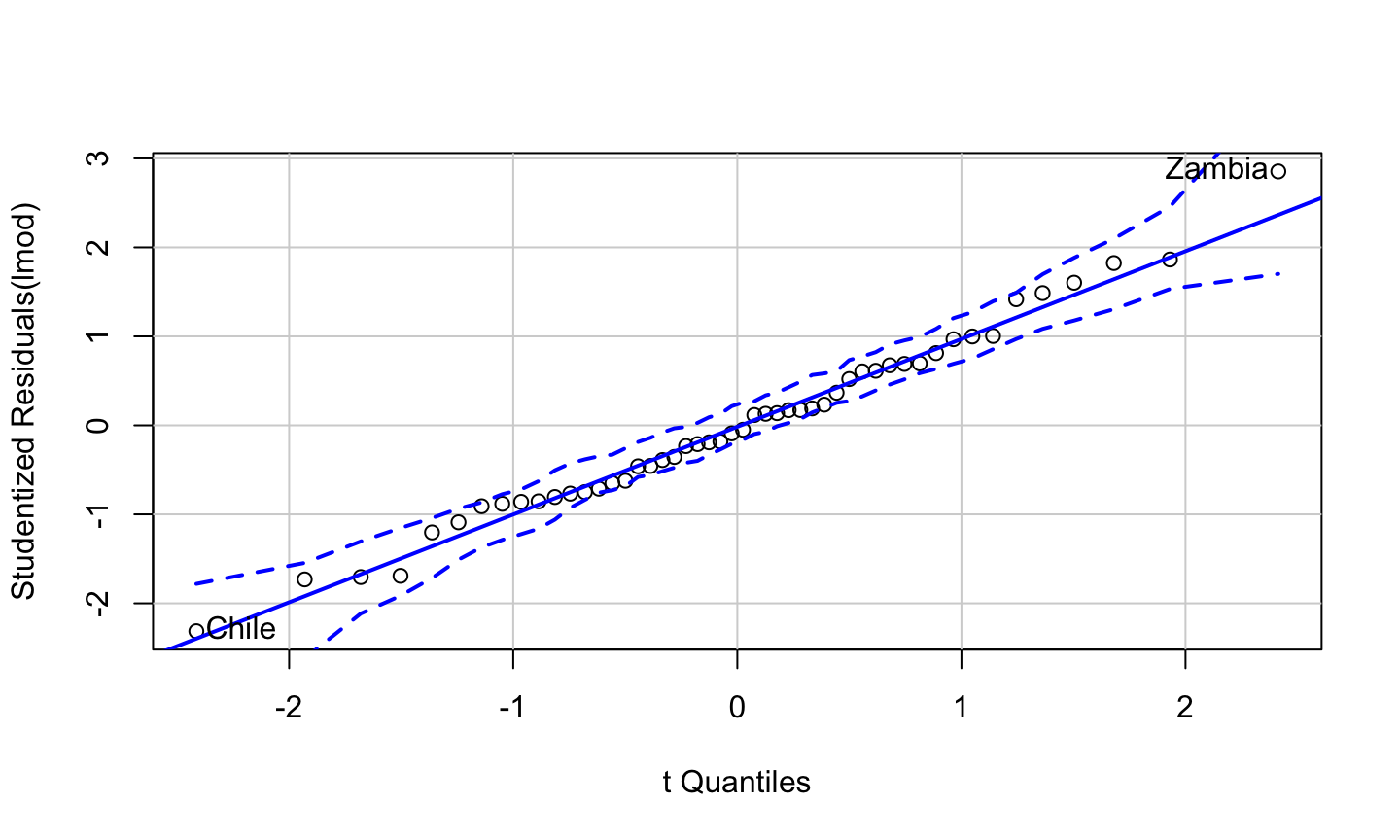
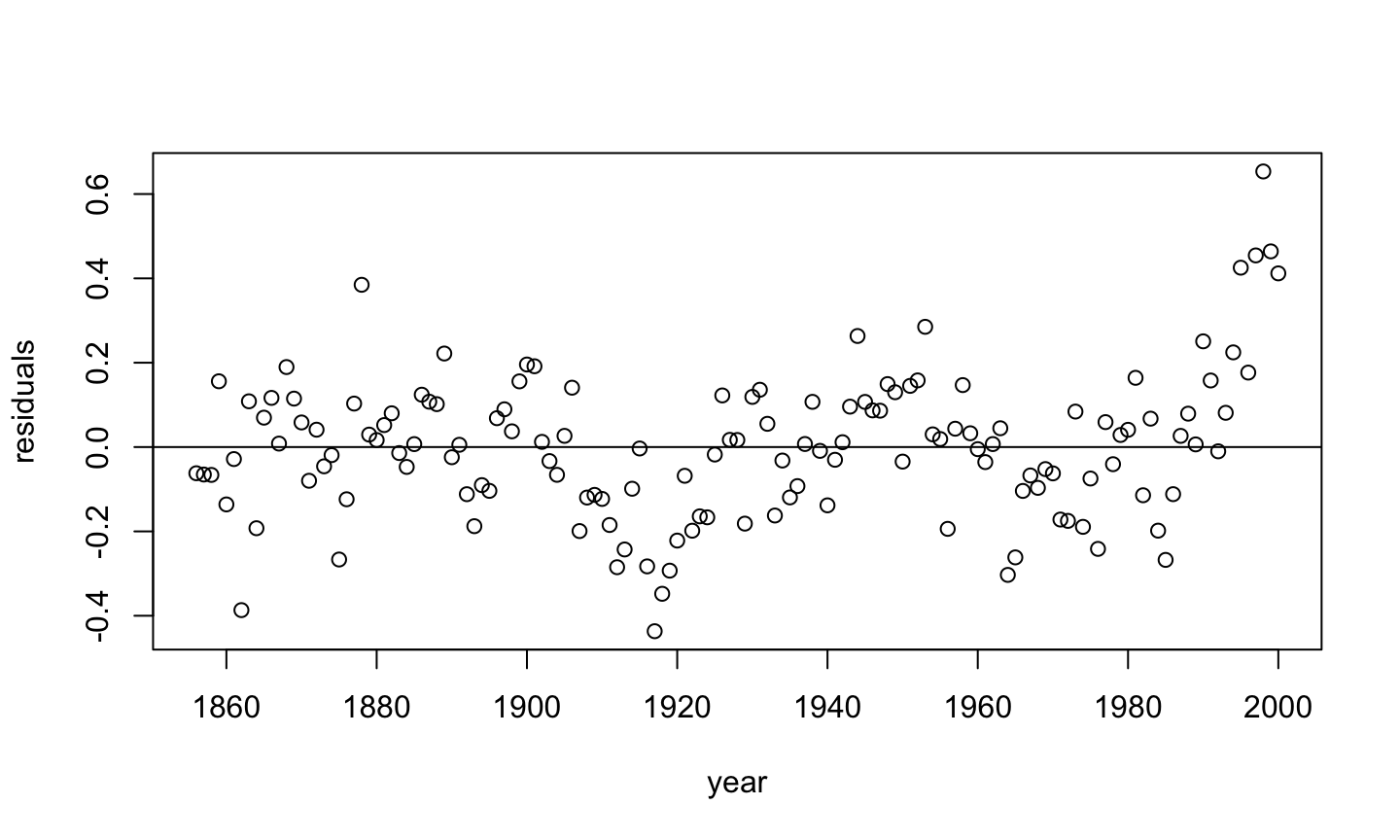
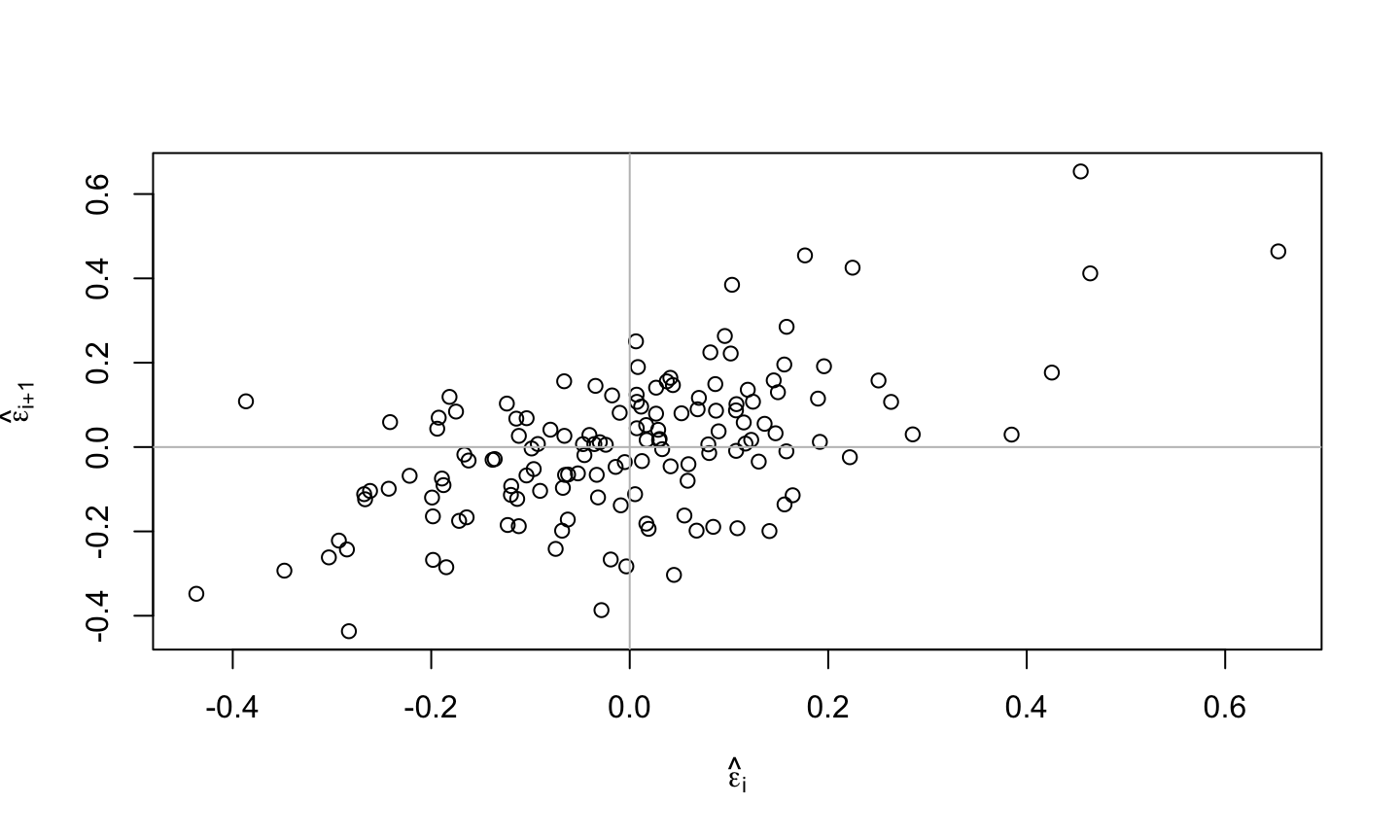
Error: \(\epsilon\sim N(0,\sigma^2 I)\), i.e., that the errors are normally distributed, independent, and identically distributed with mean 0 and variance \(\sigma^2\).
Unusual observations: All observations should be equally reliable and have approximately equal role in determining the regression results and in influencing conclusions.