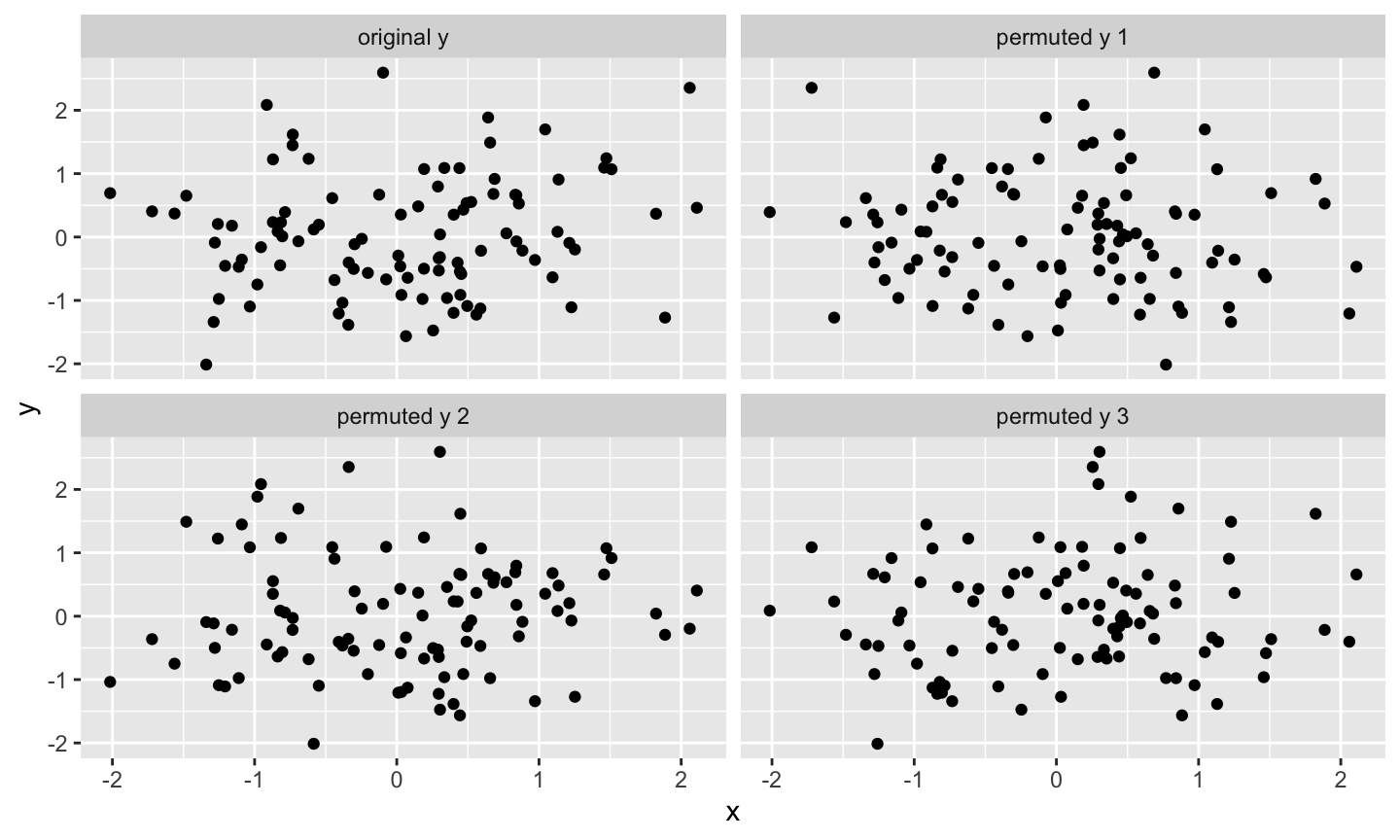
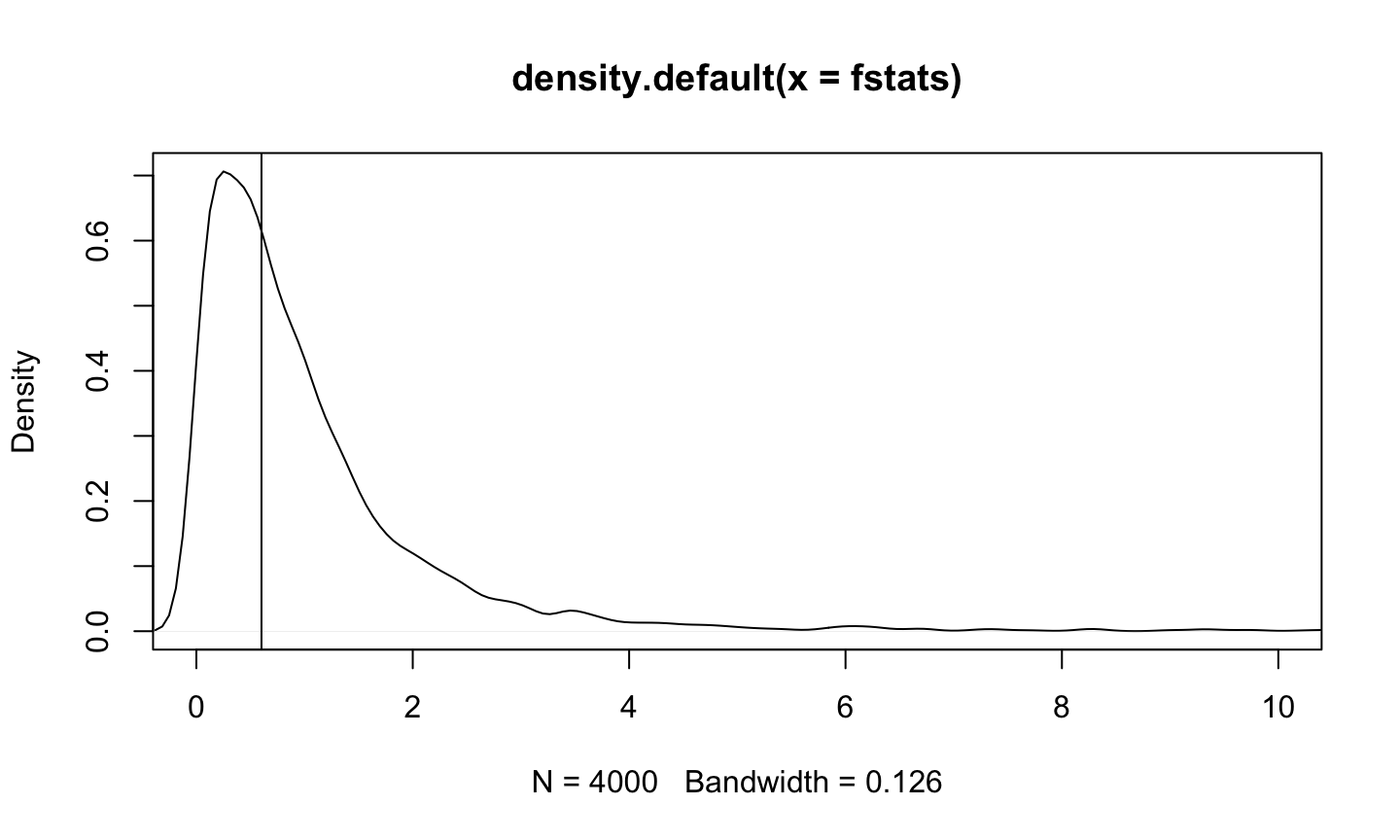
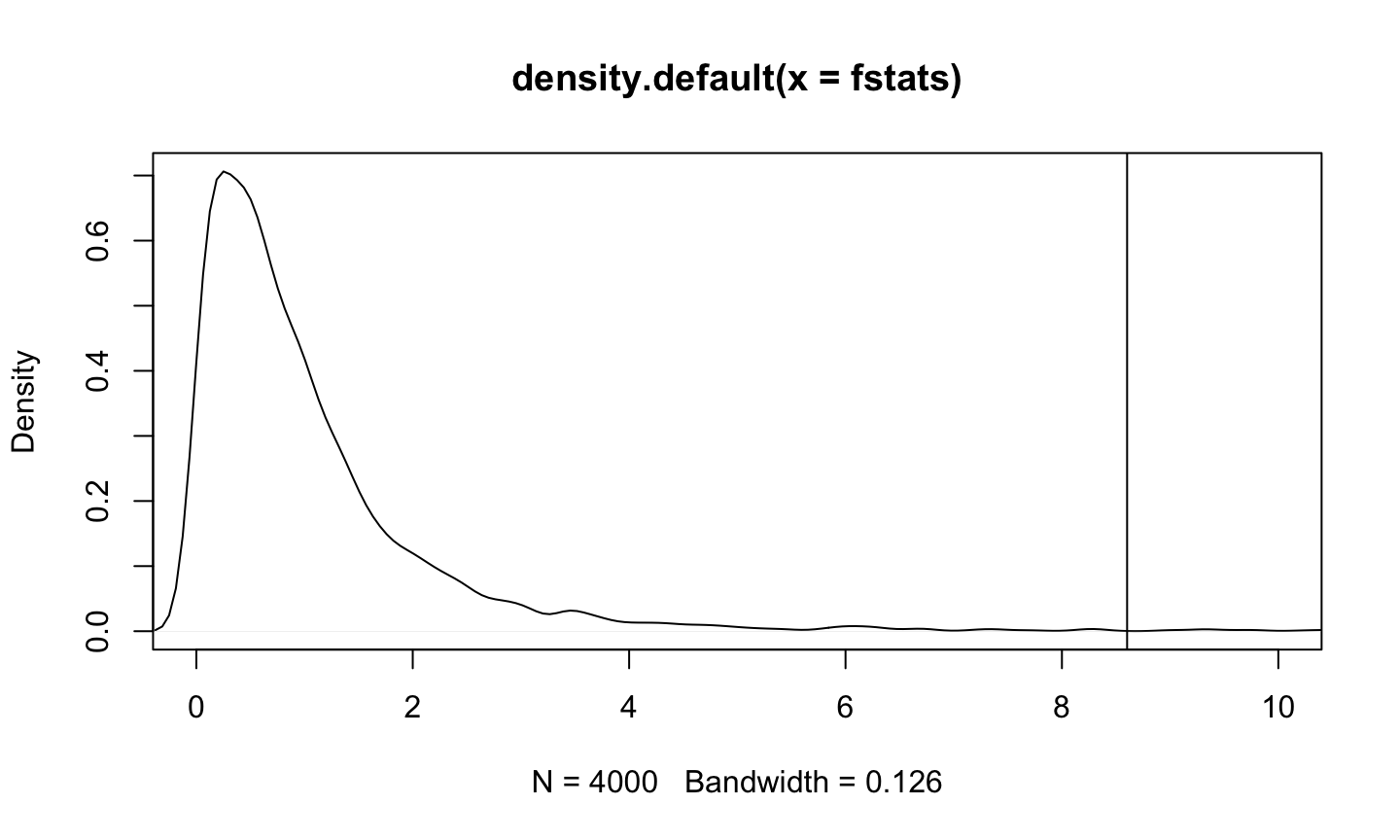
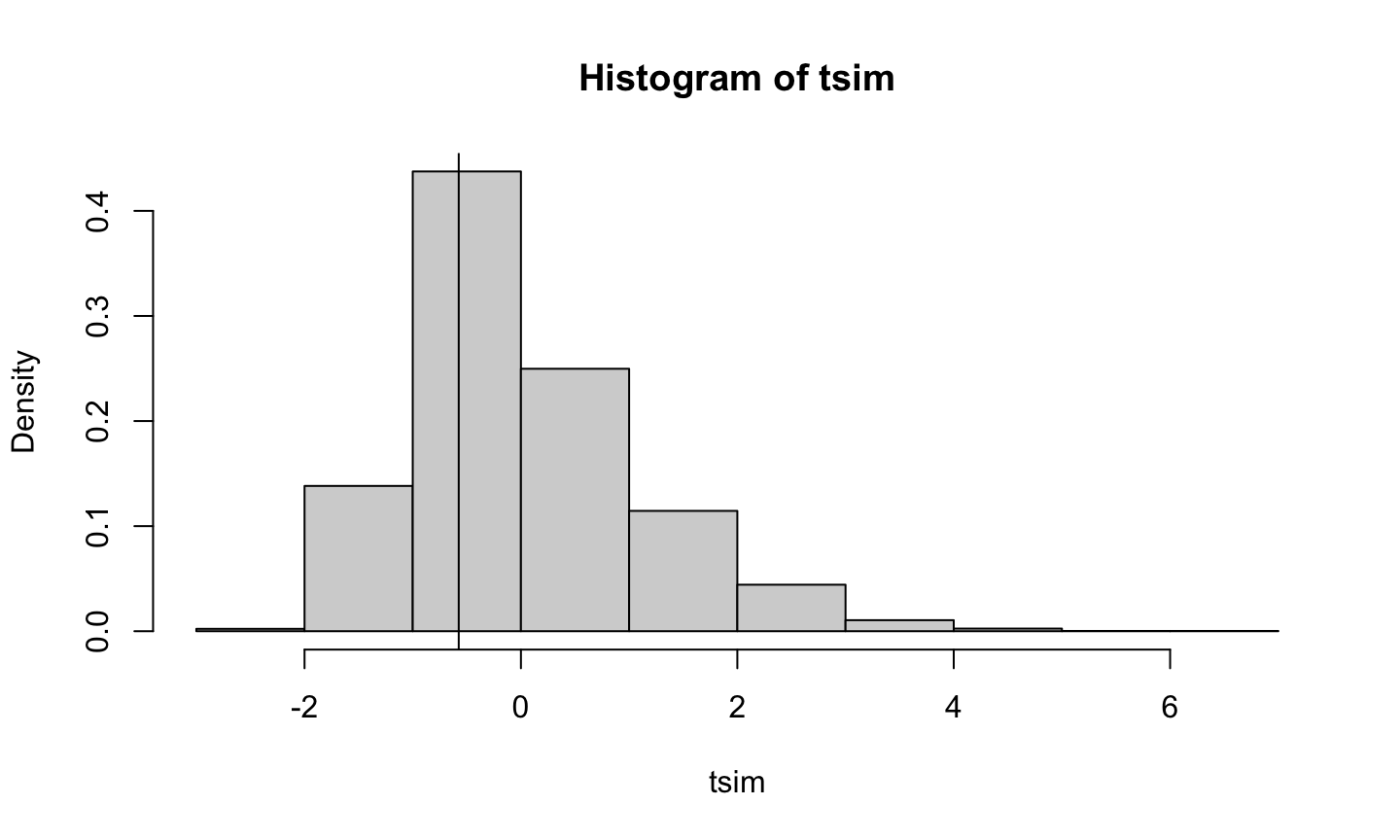
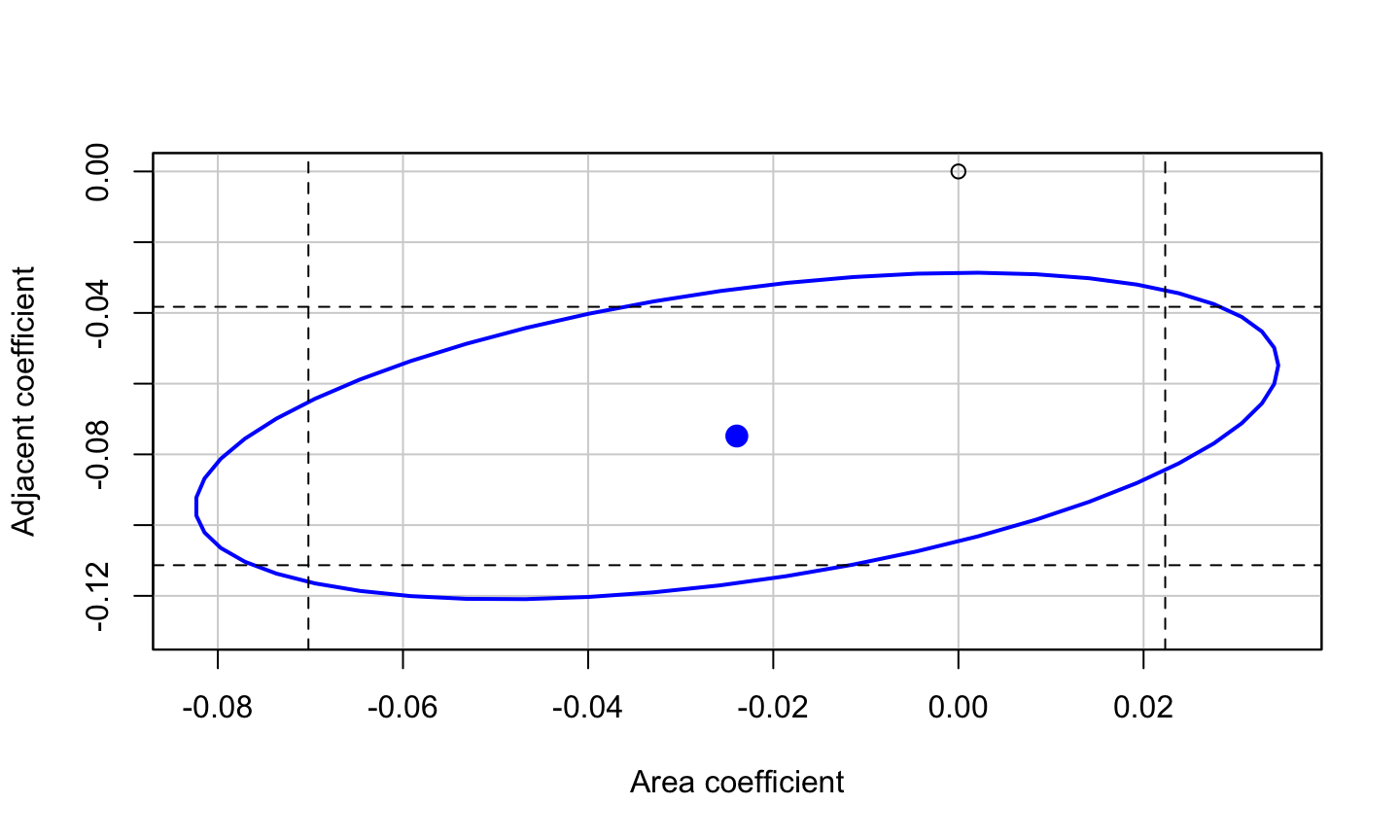
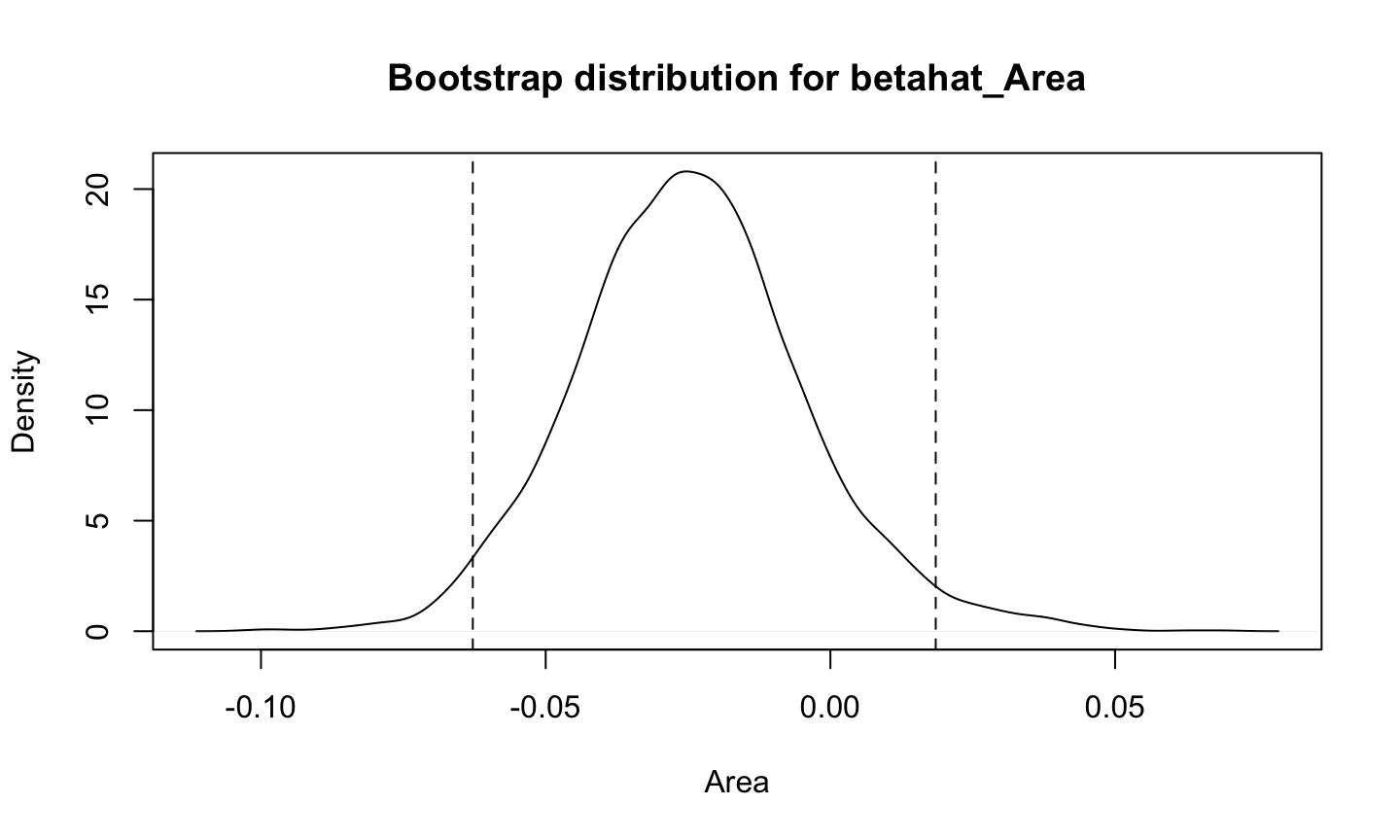
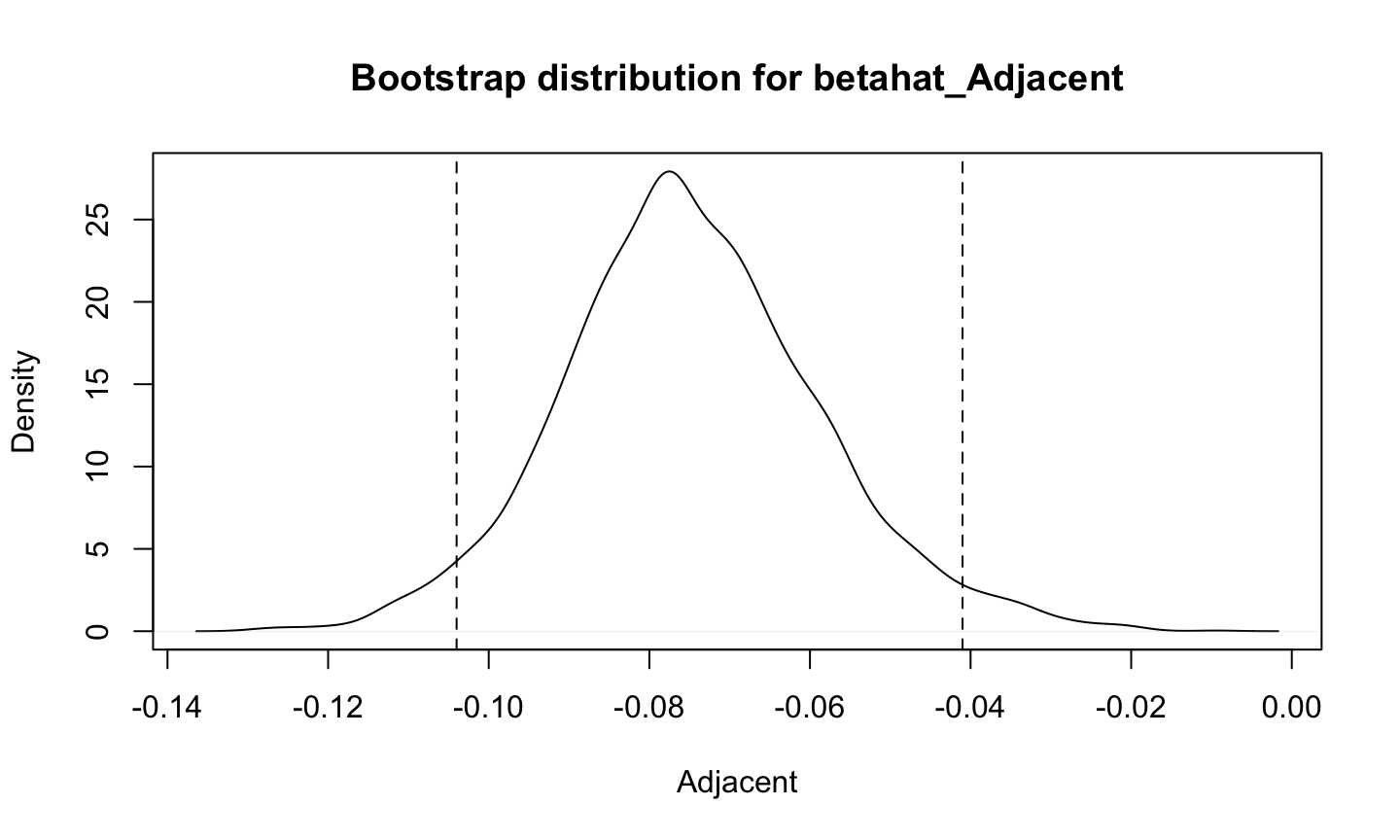
Statistical tests and confidence intervals for the regression coefficients of a linear regression model (typically) assume
\[\epsilon \sim N(0,\sigma^2I).\]
This is equivalent to \(\epsilon_1,\epsilon_2,…,\epsilon_n \sim N(0,\sigma^2)\) and i.i.d.
Unless discussing a permutation test or a bootstrap confidence interval, we will assume these assumptions are satisfied.