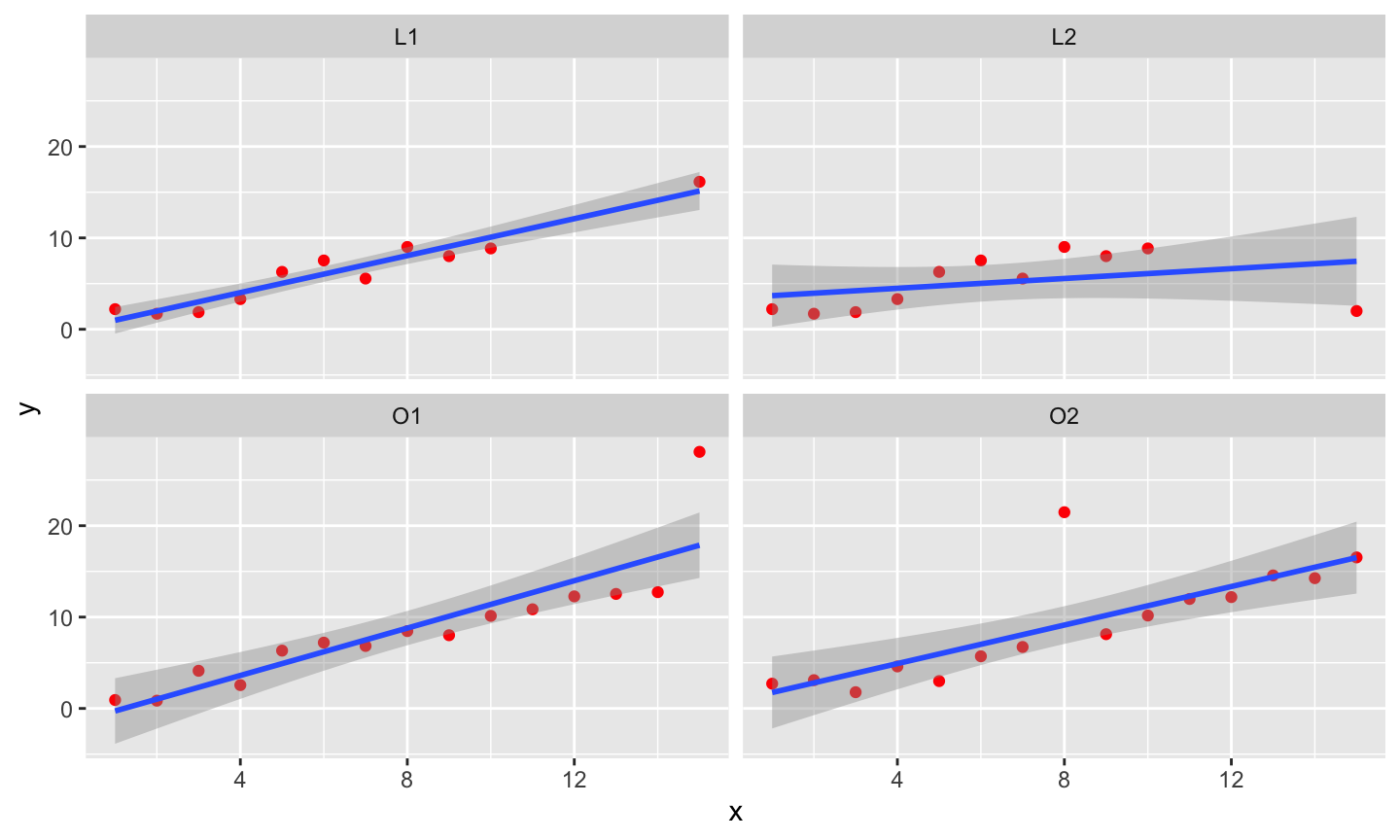
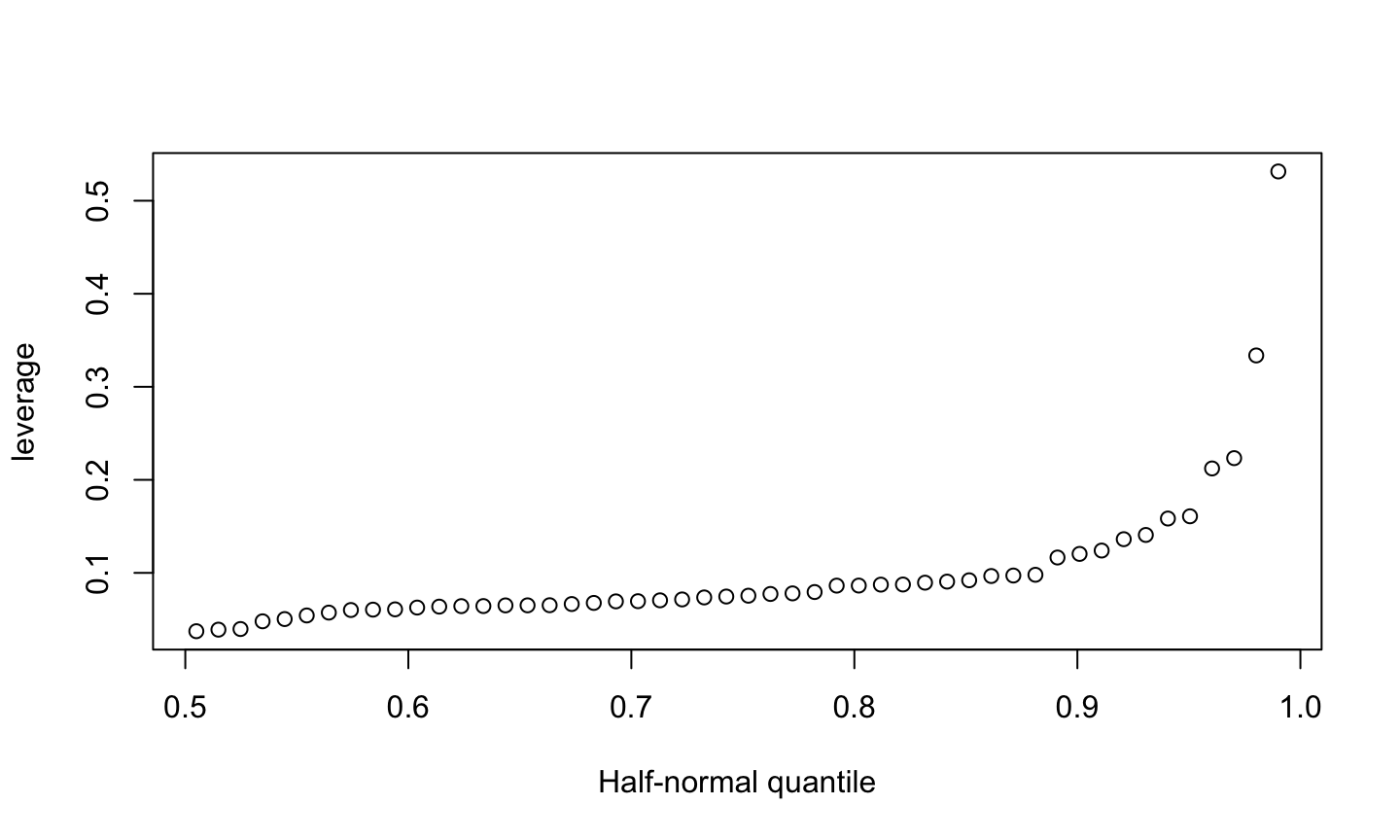
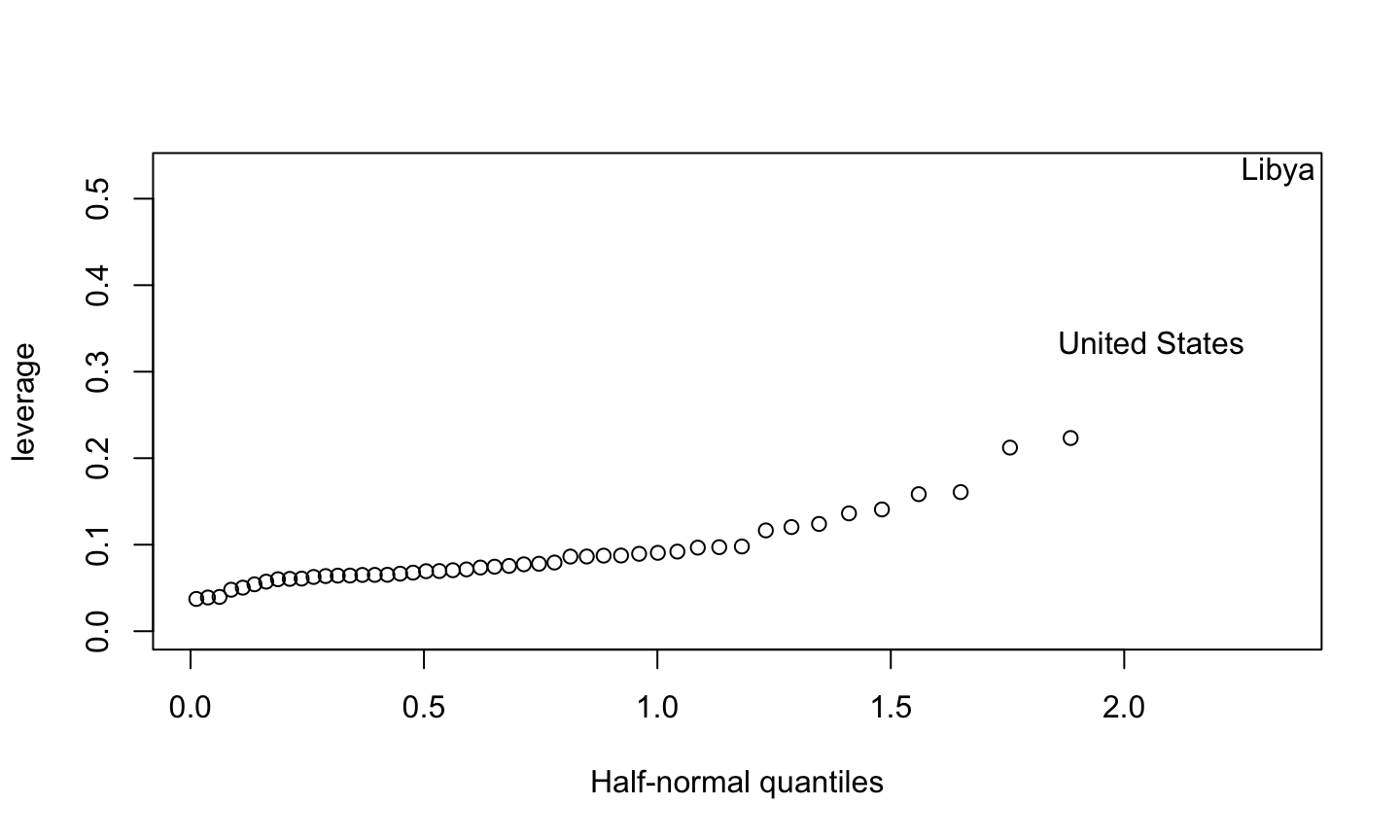
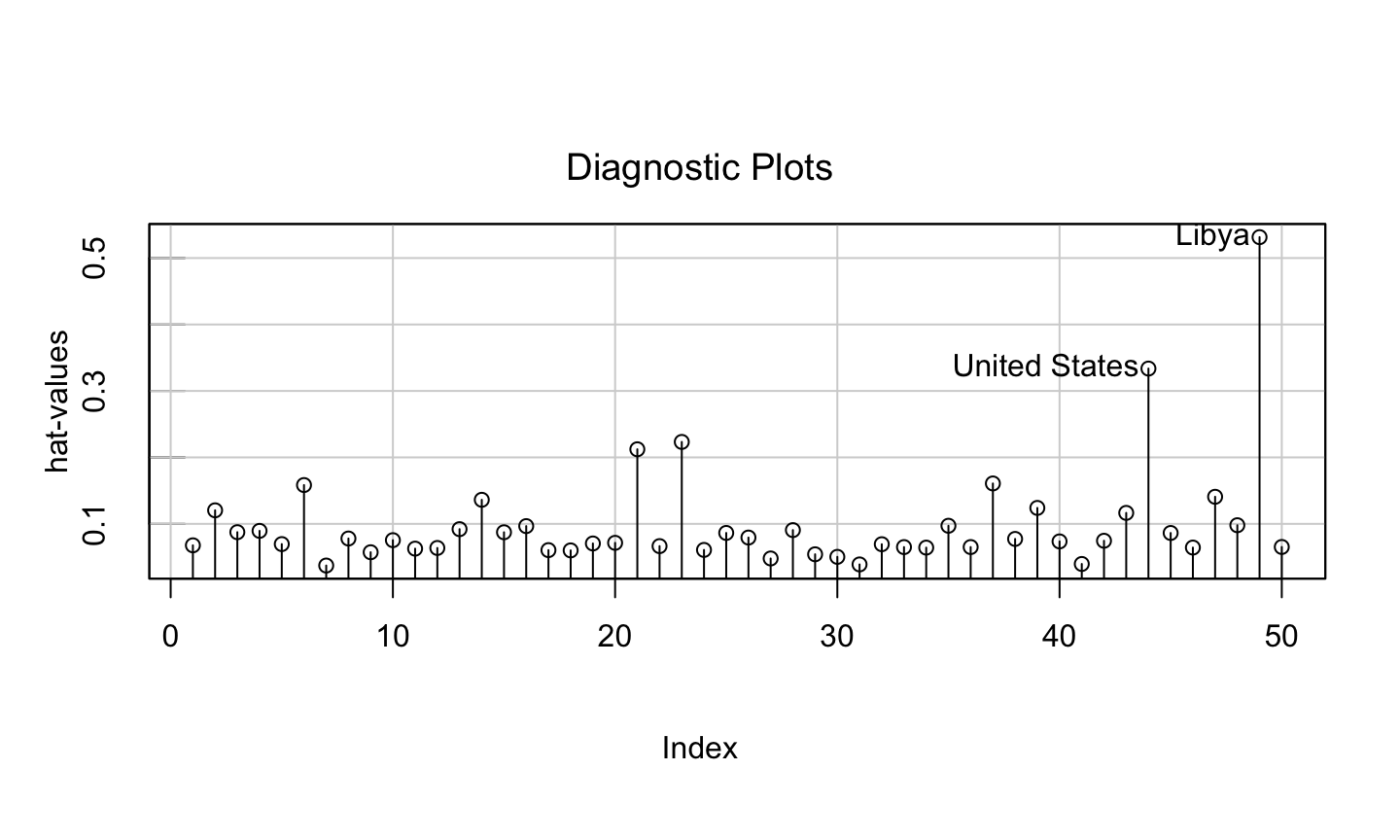
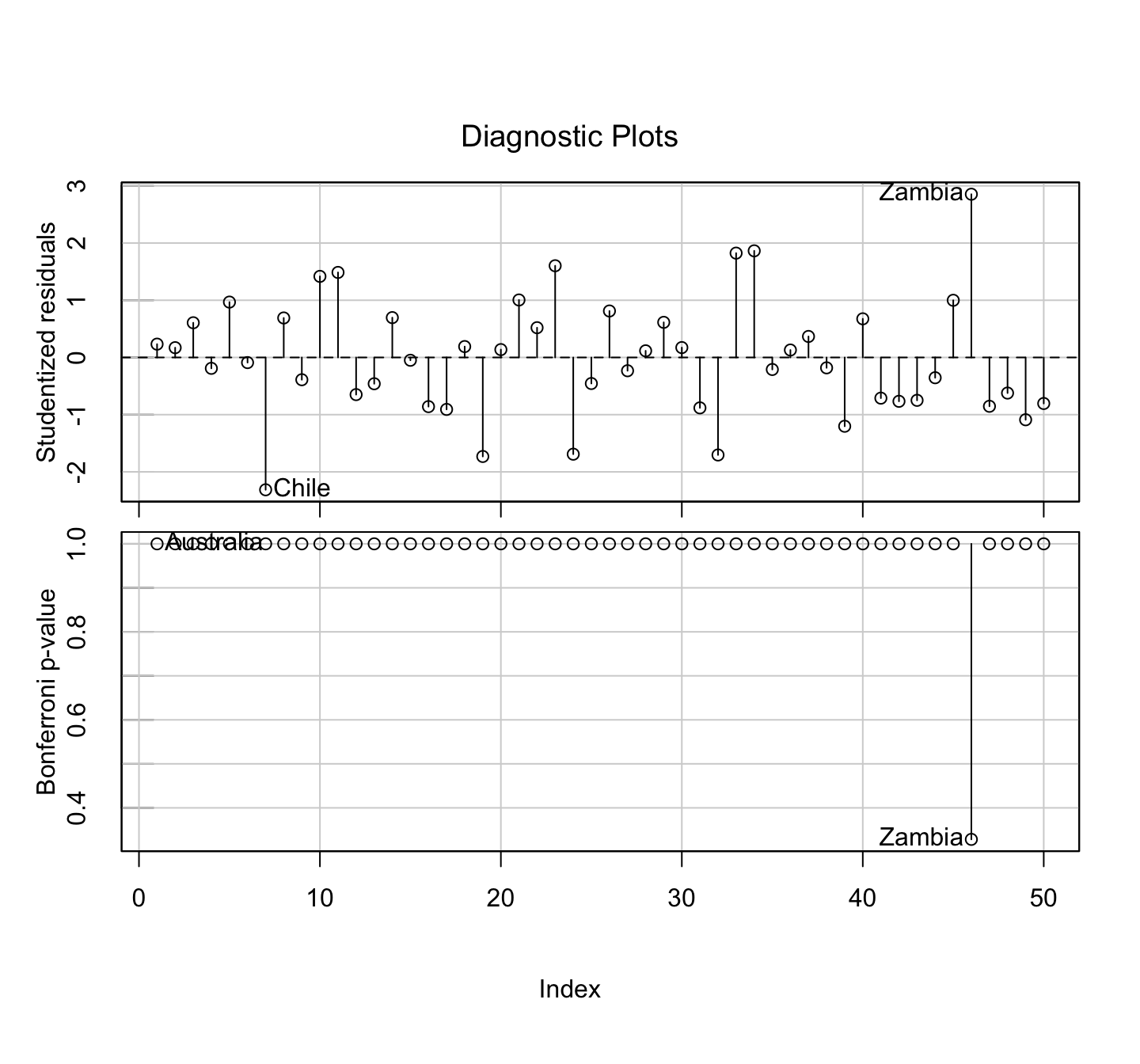
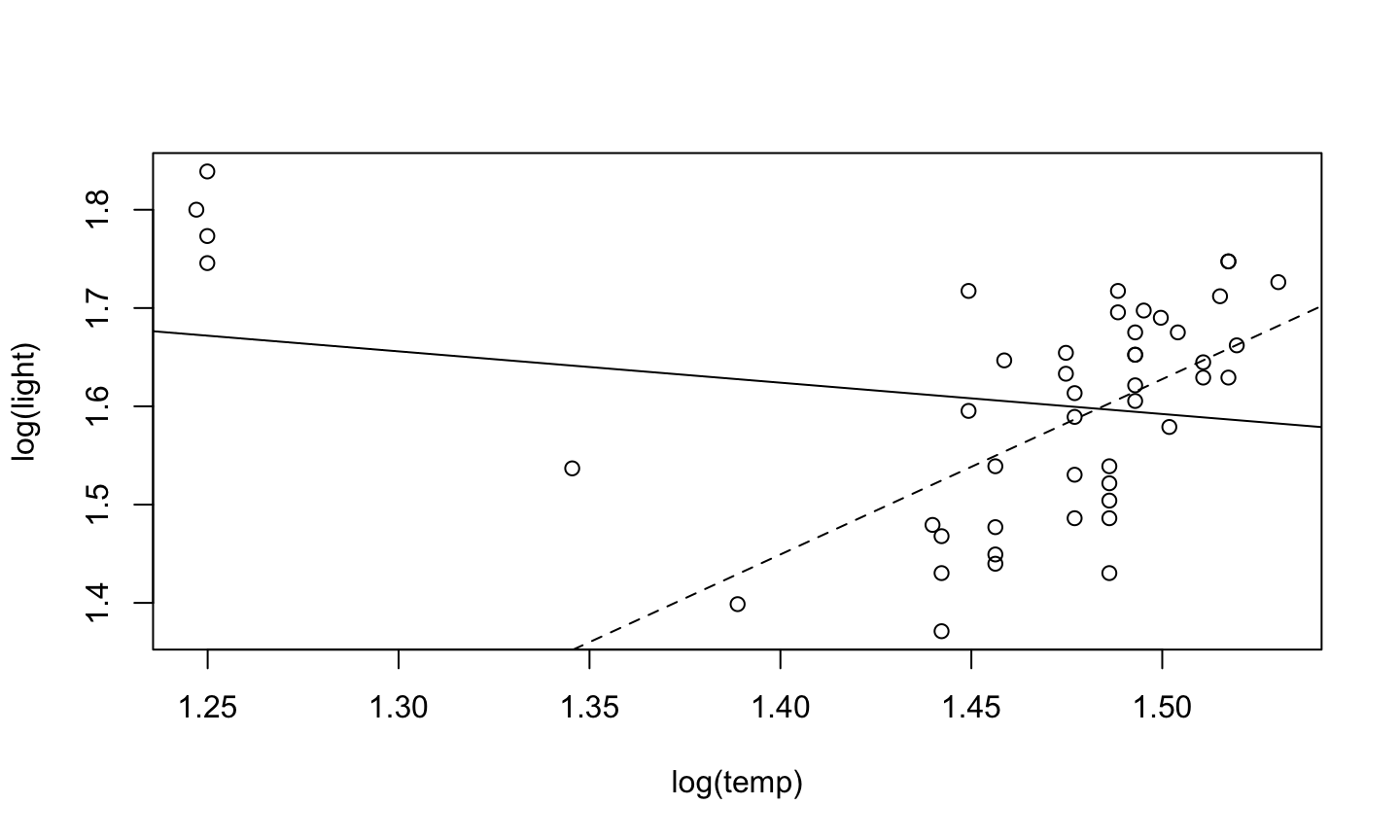
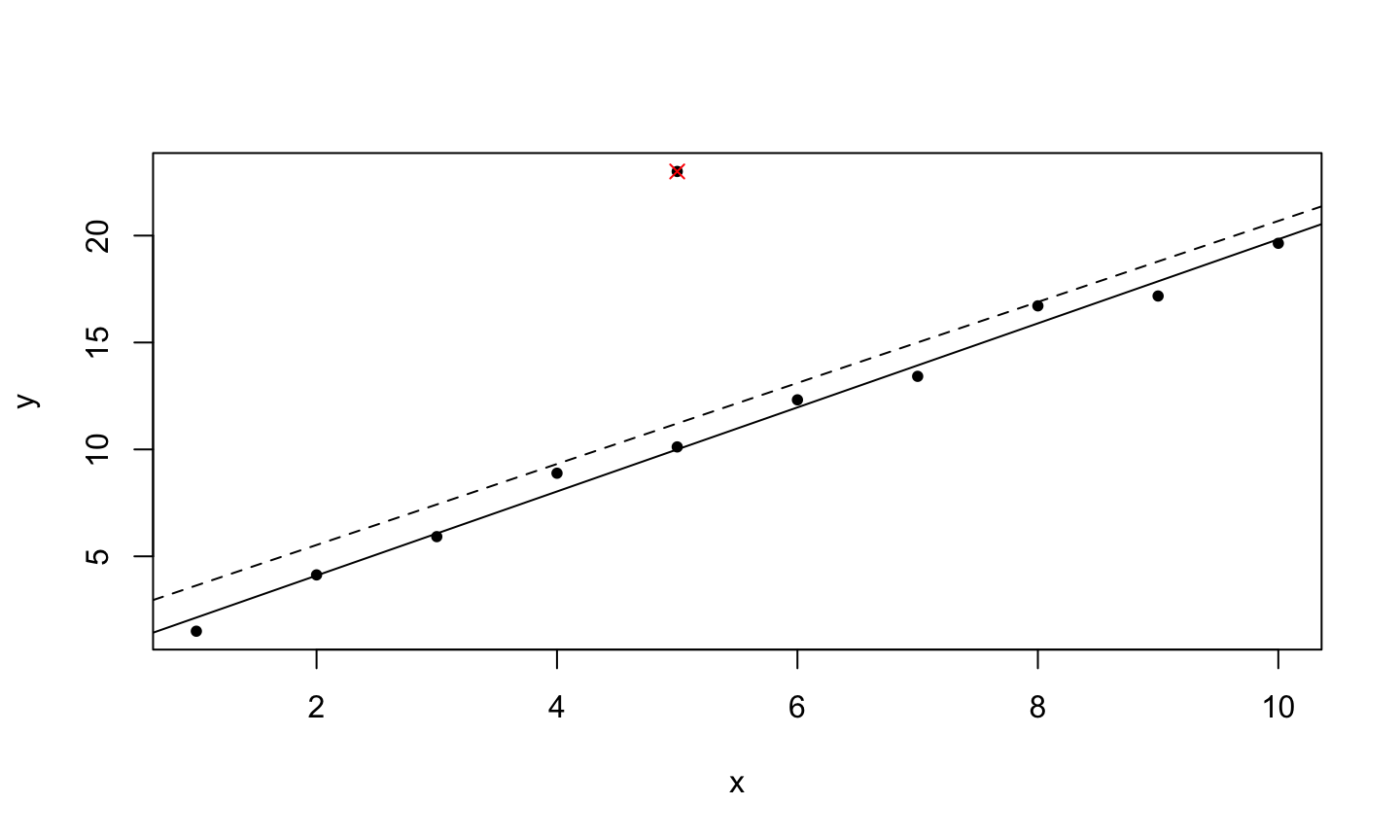
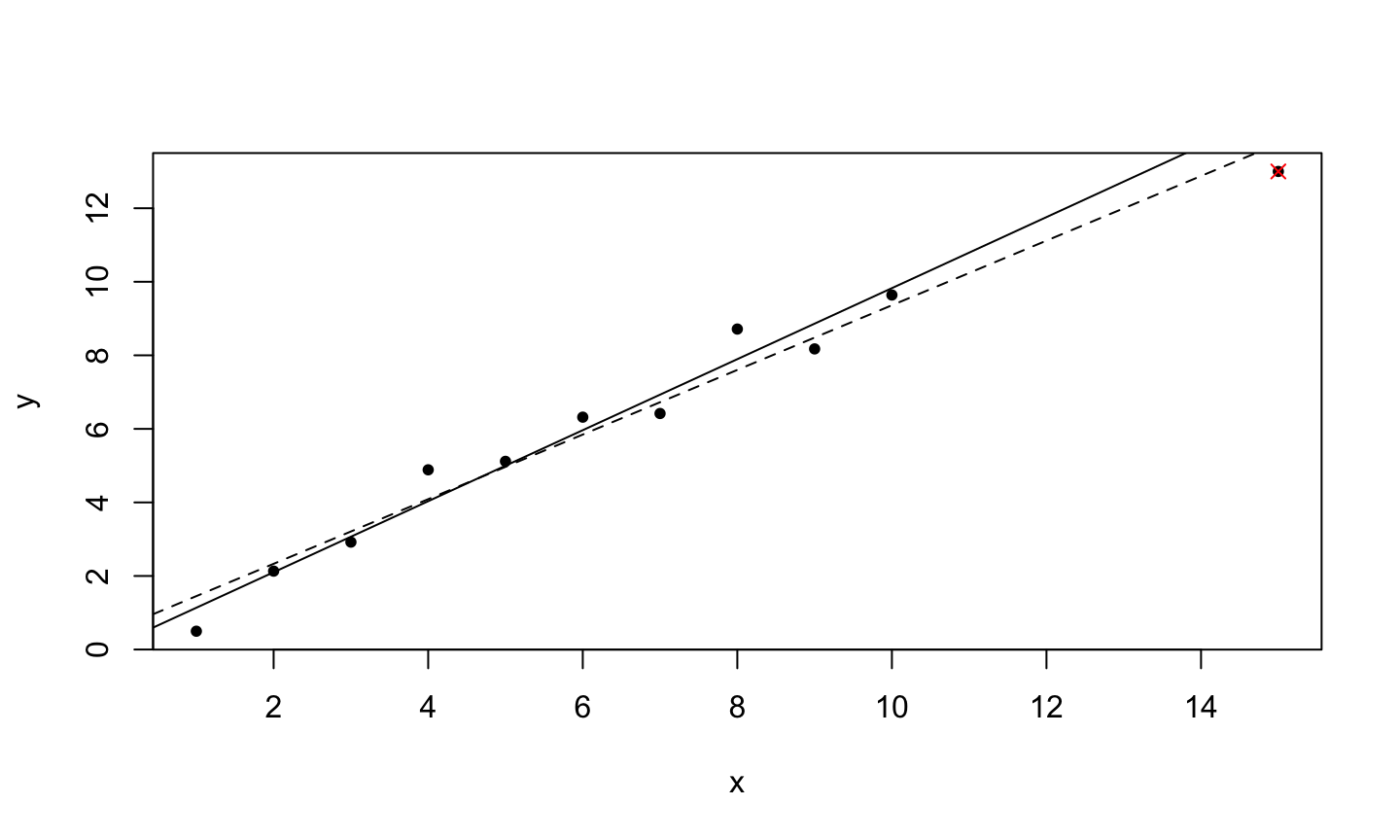
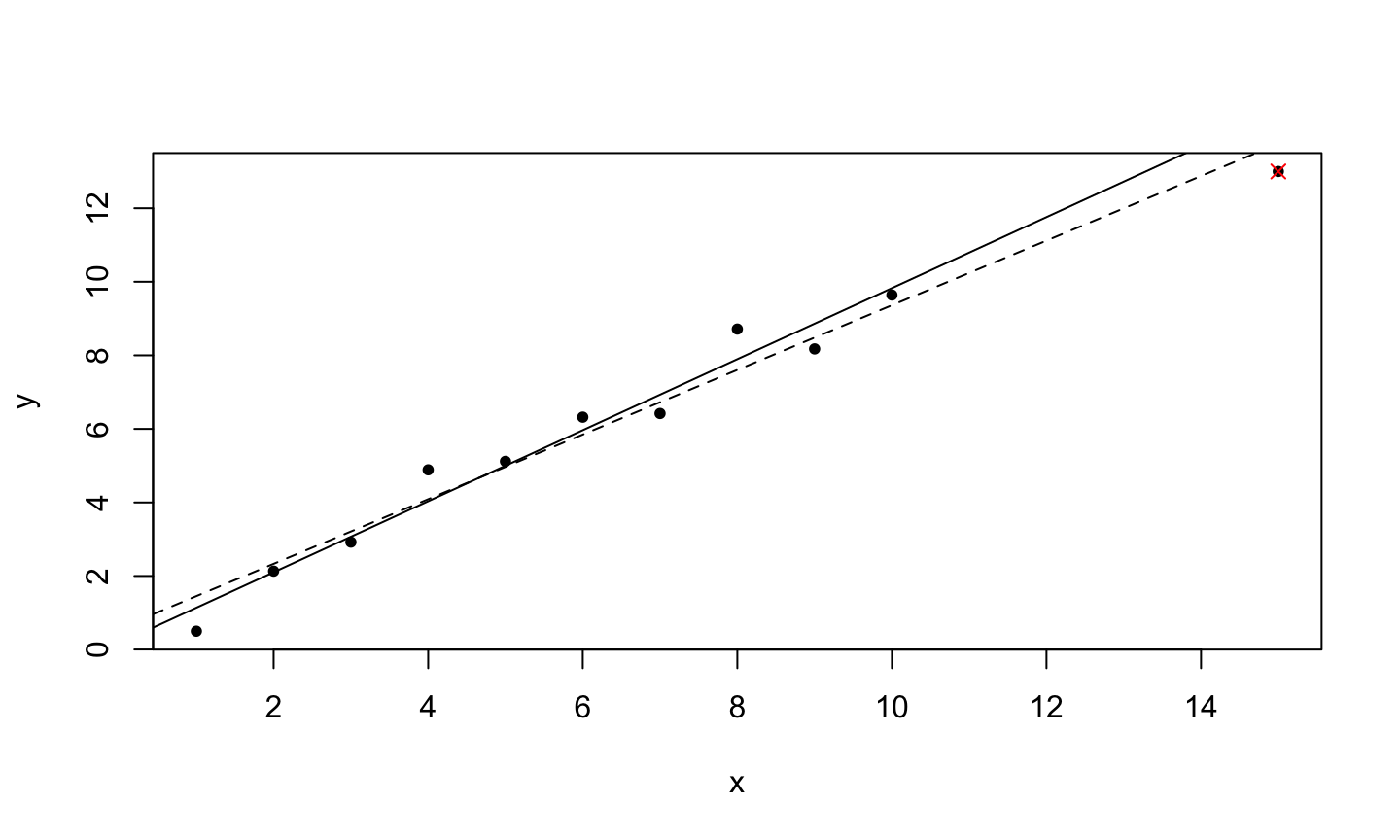
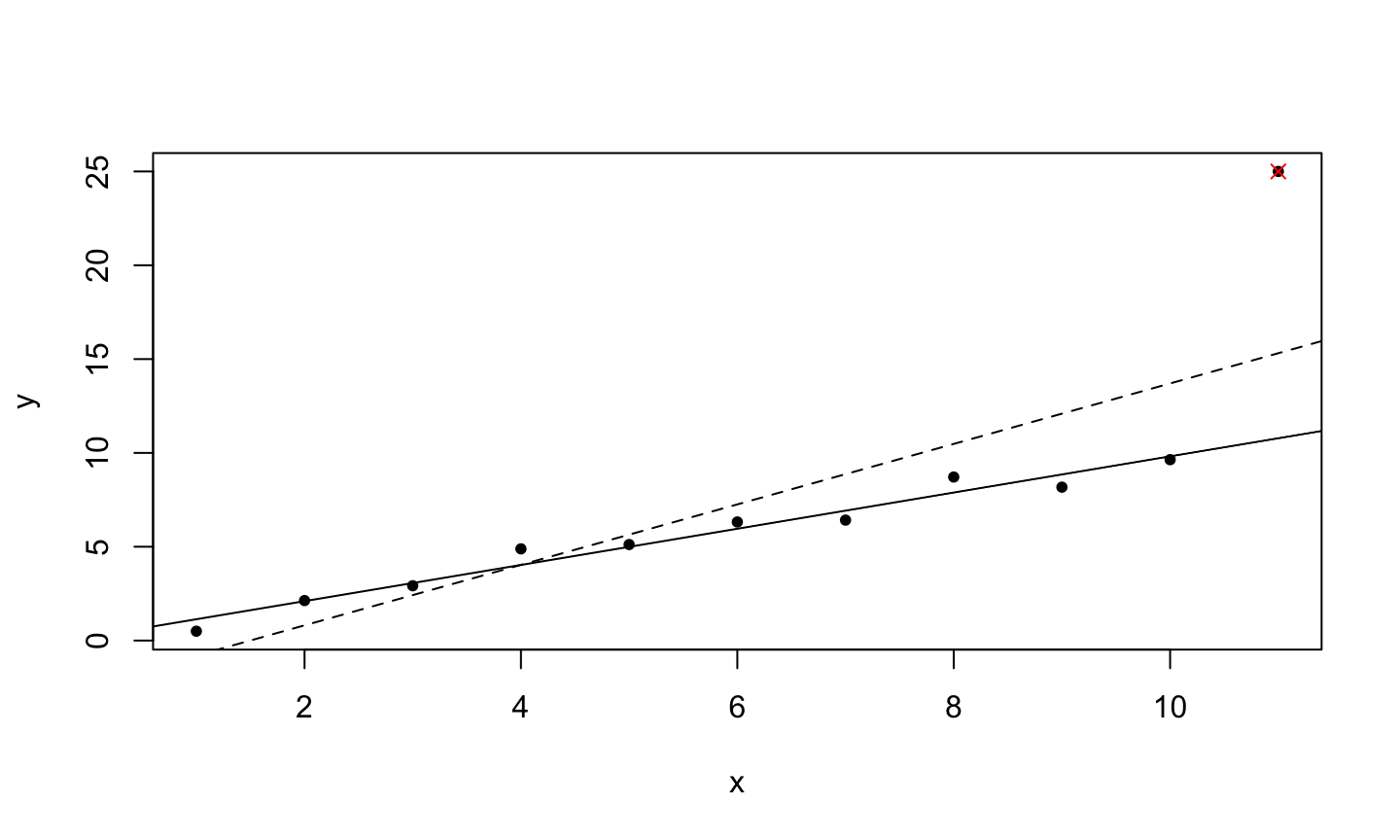
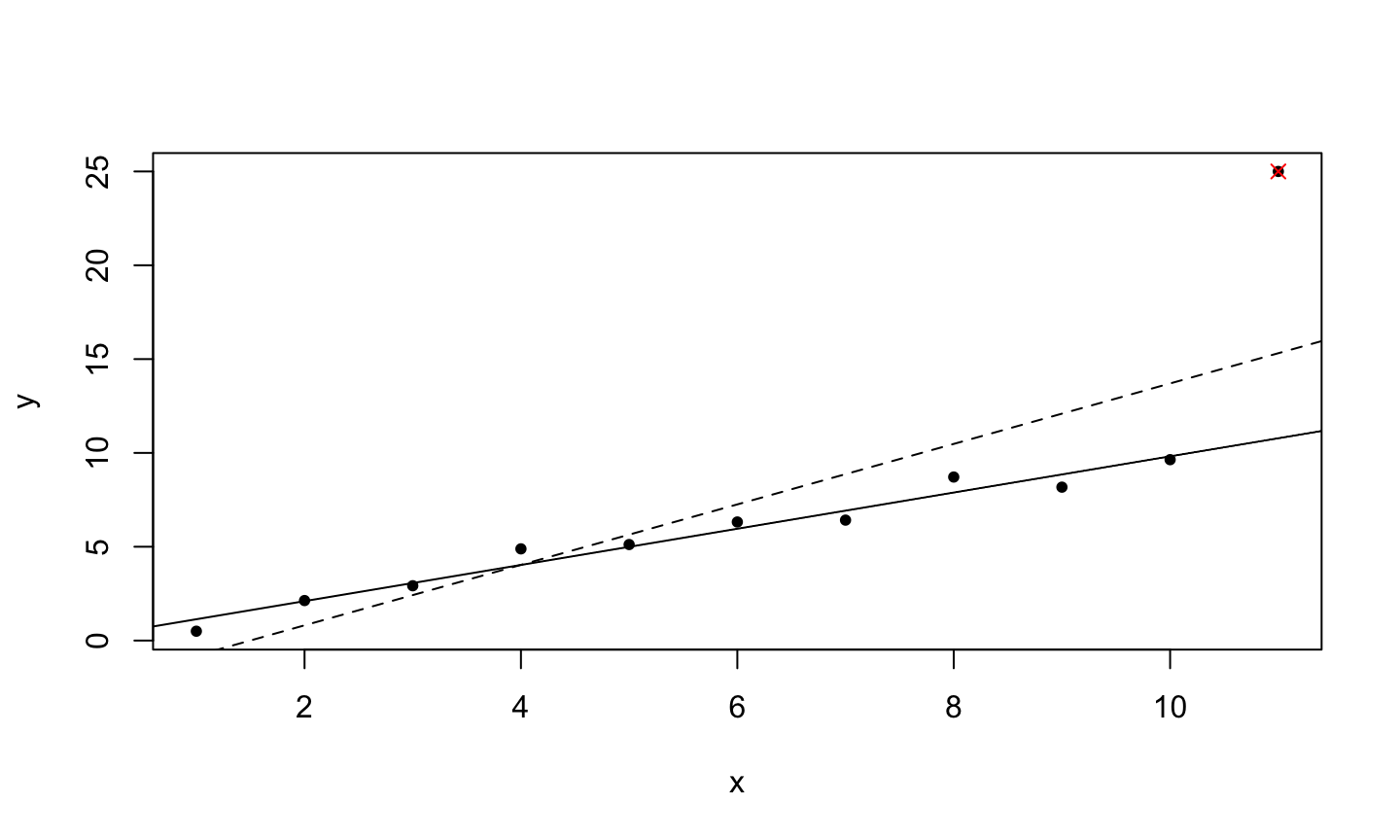
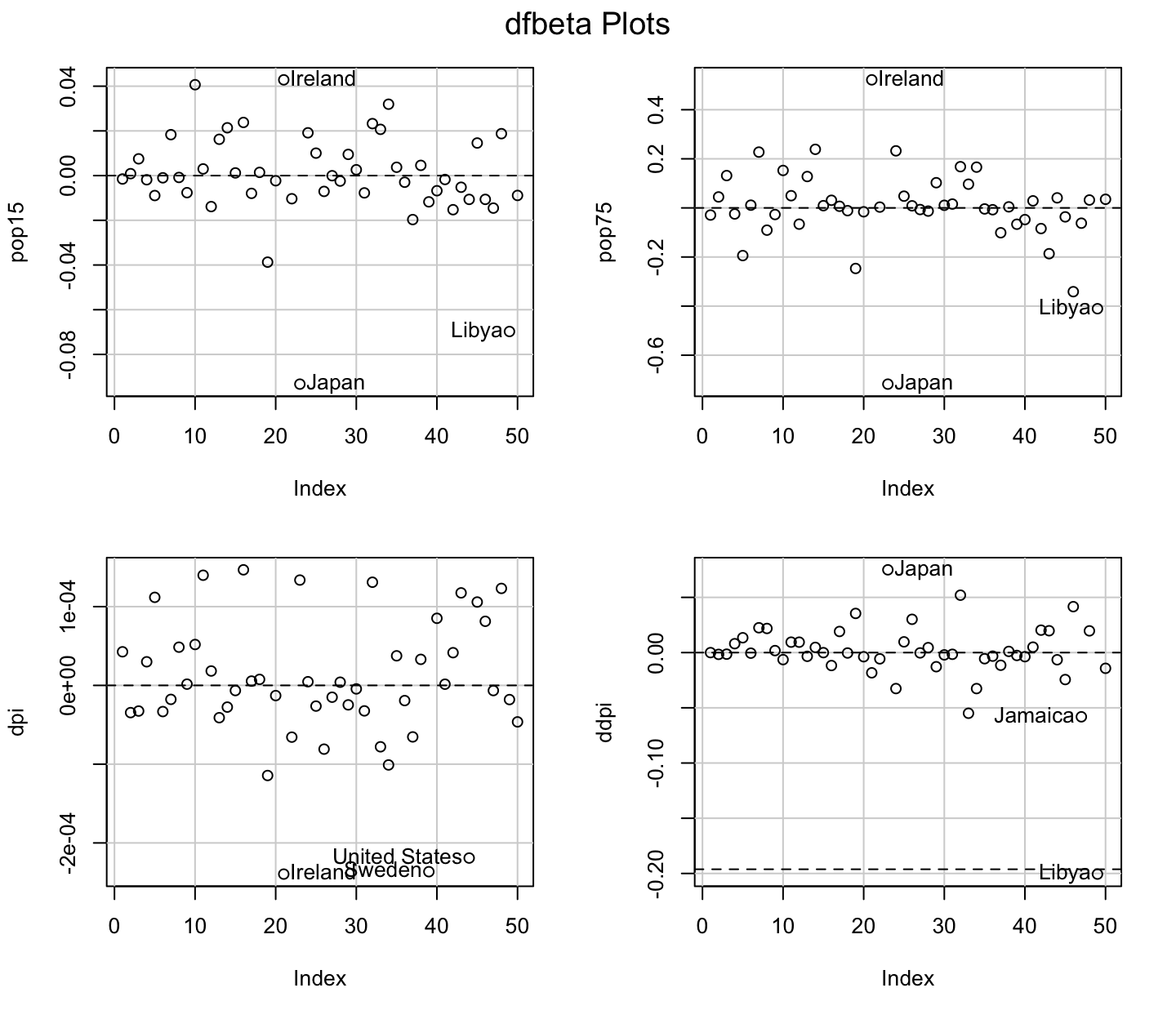
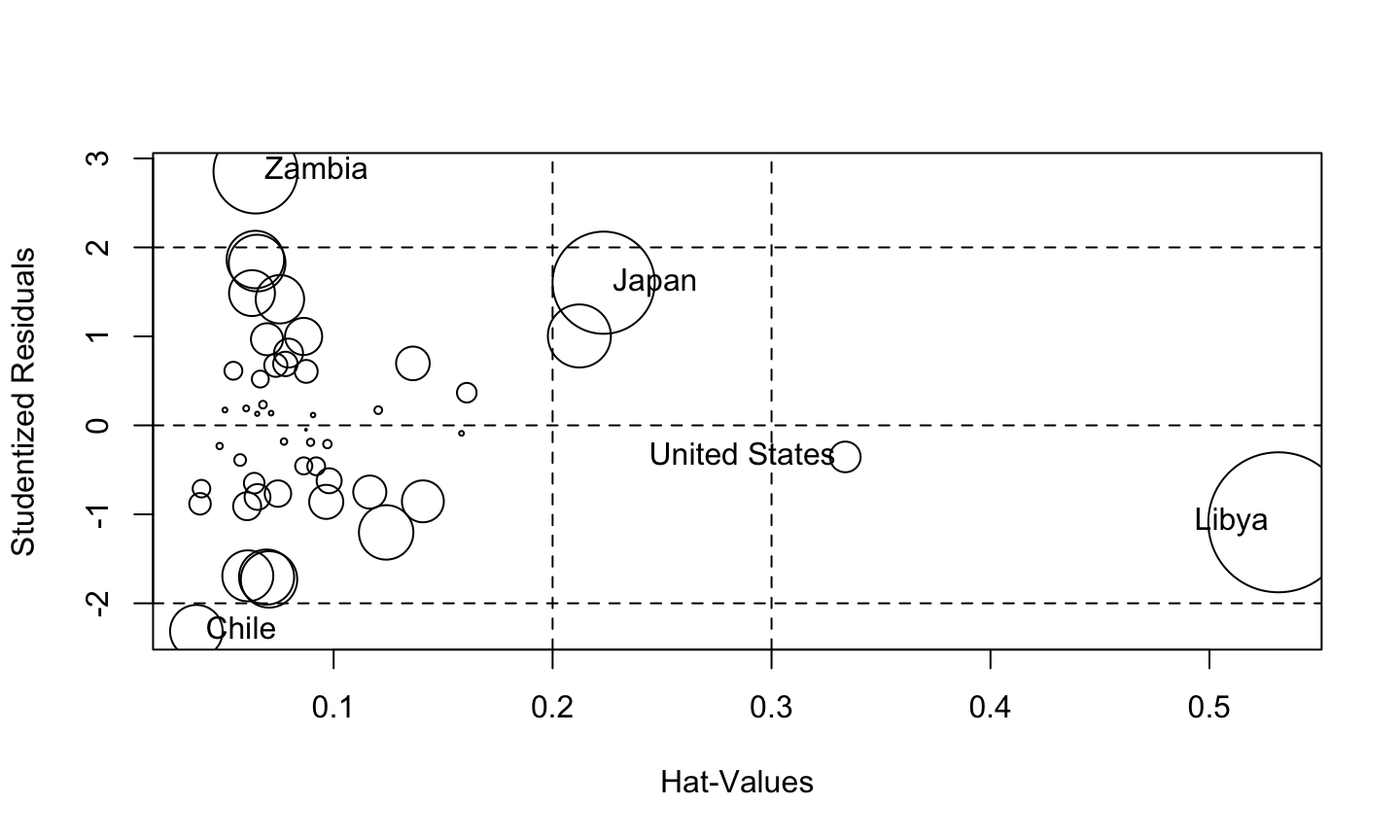
An implicit assumption made when fitting a regression model is that all observations should be equally reliable and have approximately equal role in determining the regression results and in influencing conclusions.
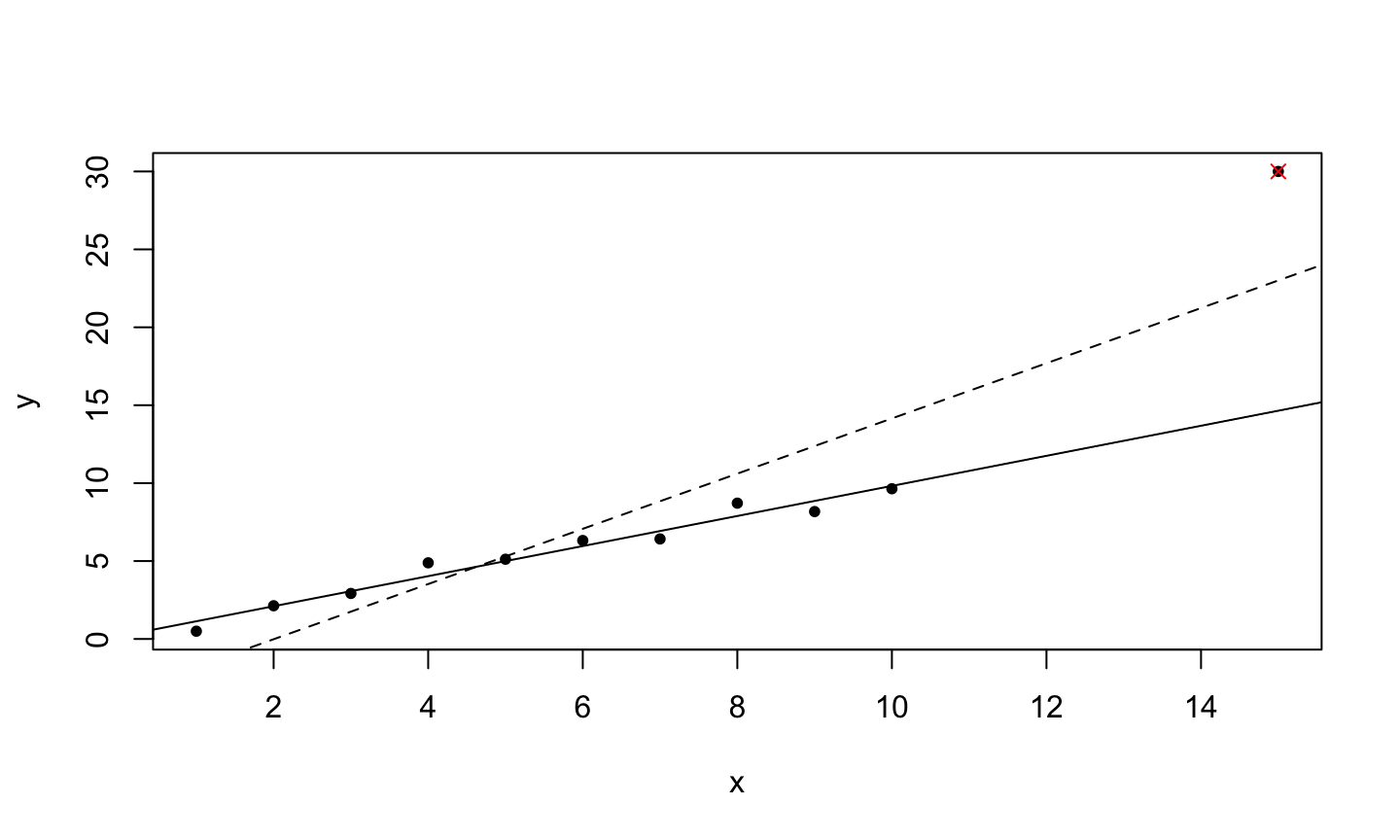
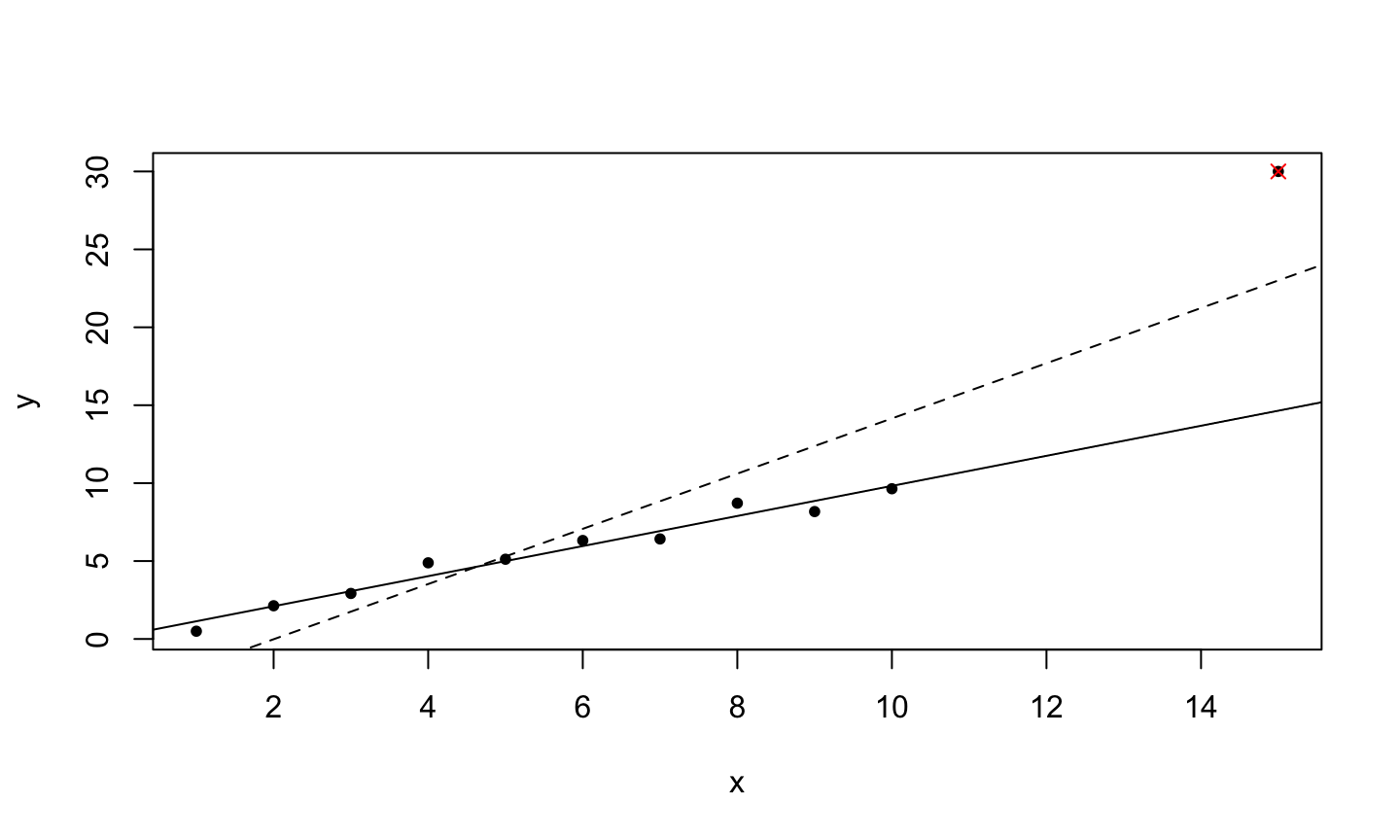
A leverage point is an observation that is unusual in the predictor space.
An outlier is an observation whose response does not match the pattern of the fitted model.
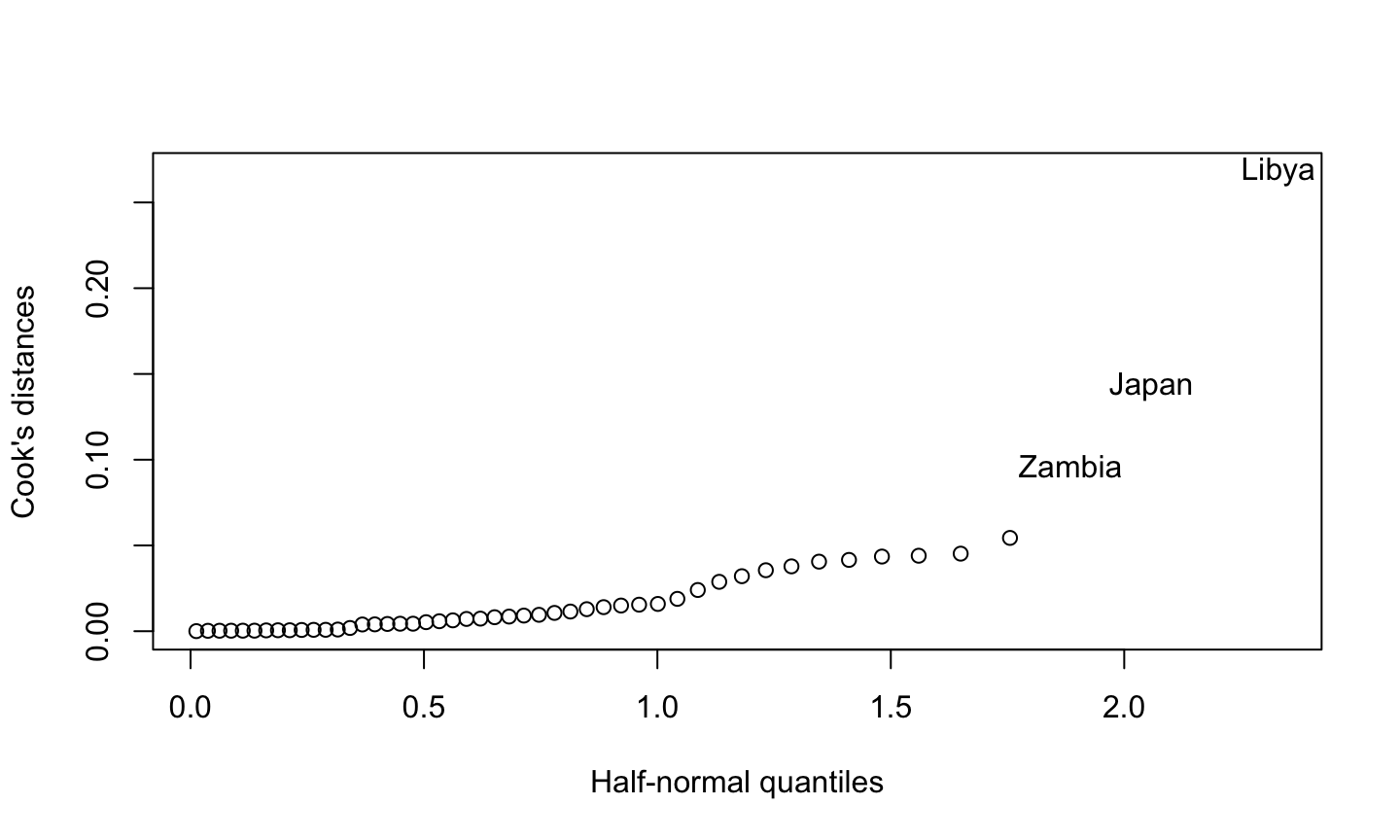
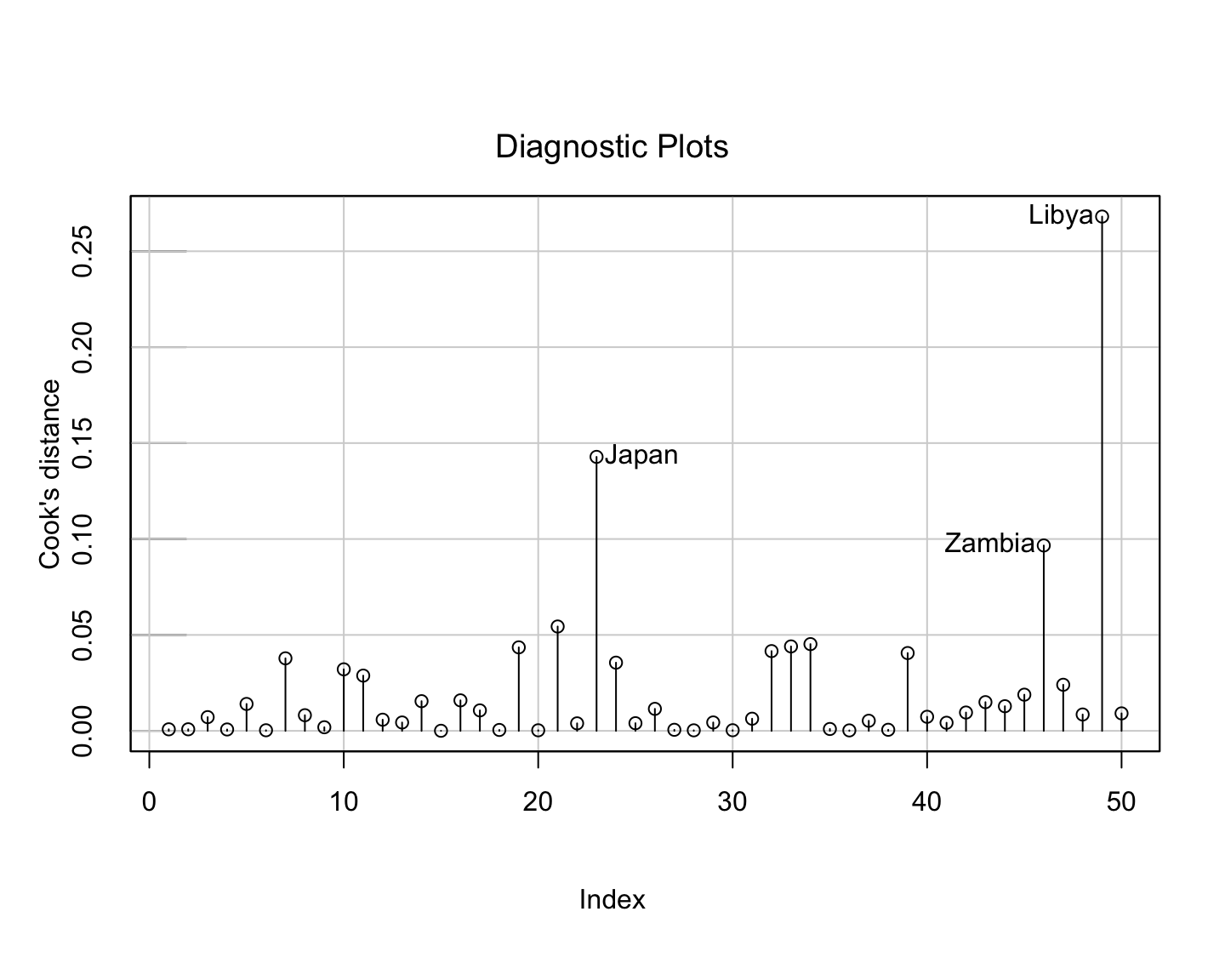
An influential observation is one that causes a substantial change in the fitted model based on its inclusion or deletion from the model.
- An influential observation is usually either a leverage point, an outlier, or a combination of the two.