# compare mse (rmse) for the two models using 10-fold cv
print(modela$results) # full, 10-fold
## intercept RMSE Rsquared MAE RMSESD RsquaredSD MAESD
## 1 TRUE 0.8559381 0.5932933 0.7133981 0.2849117 0.3111669 0.2432284
print(modelb$results) # reduced, 10-fold
## intercept RMSE Rsquared MAE RMSESD RsquaredSD MAESD
## 1 TRUE 0.730817 0.7332559 0.6239986 0.2149312 0.2036376 0.201853
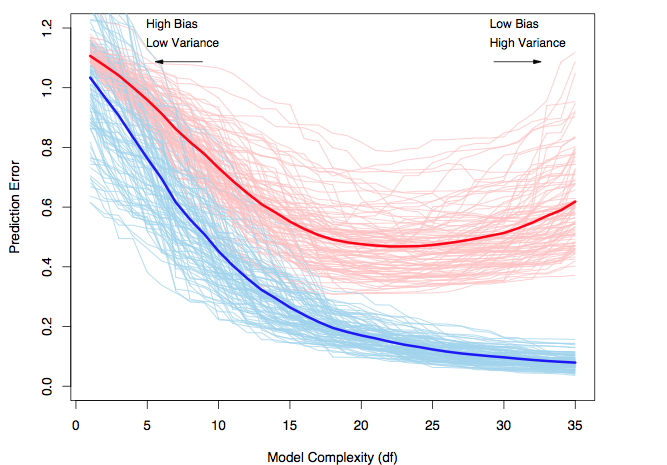
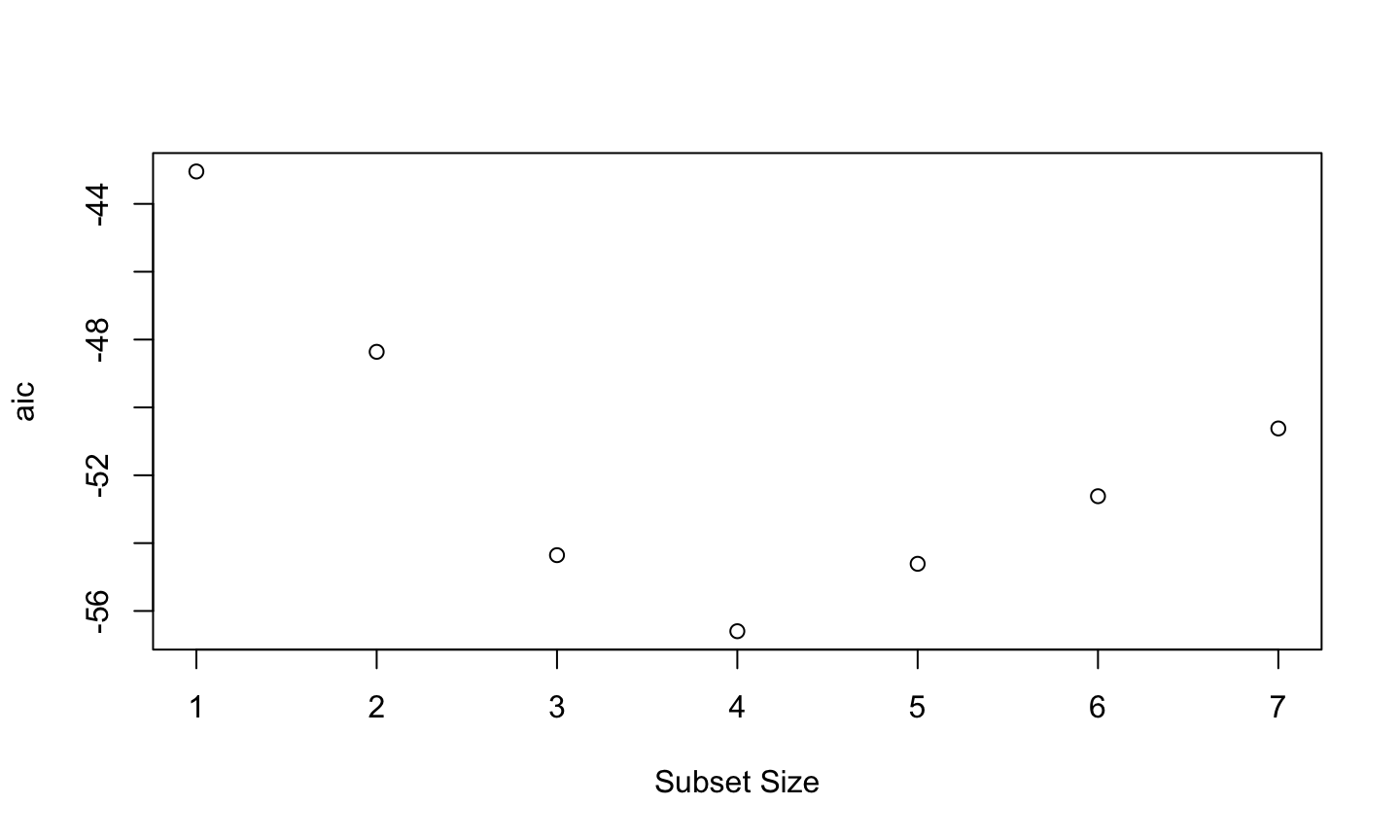
The smaller model is preferred (since it has smaller RMSE) using 10-fold crossvalidation.
modelc = train(f1, data = statedata, trControl = cv_loo,
method = "lm")
modeld = train(f2, data = statedata, trControl = cv_loo,
method = "lm")
# compare mse (rmse) for the two models using 10-fold cv
print(modelc$results) # full 2, LOO
## intercept RMSE Rsquared MAE
## 1 TRUE 0.9090885 0.5469535 0.7196334
print(modeld$results) # reduced 2, LOO
## intercept RMSE Rsquared MAE
## 1 TRUE 0.770042 0.6657615 0.6377097
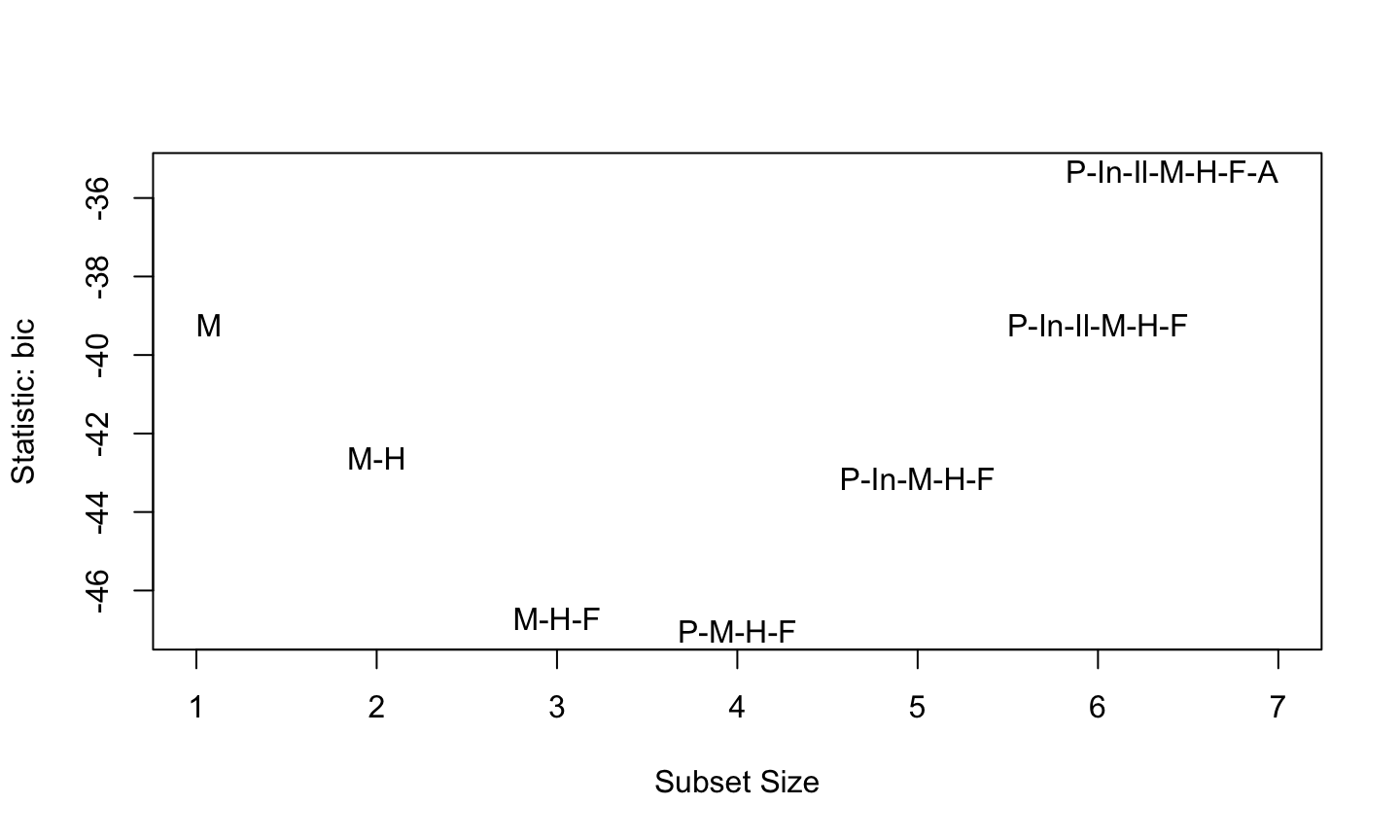
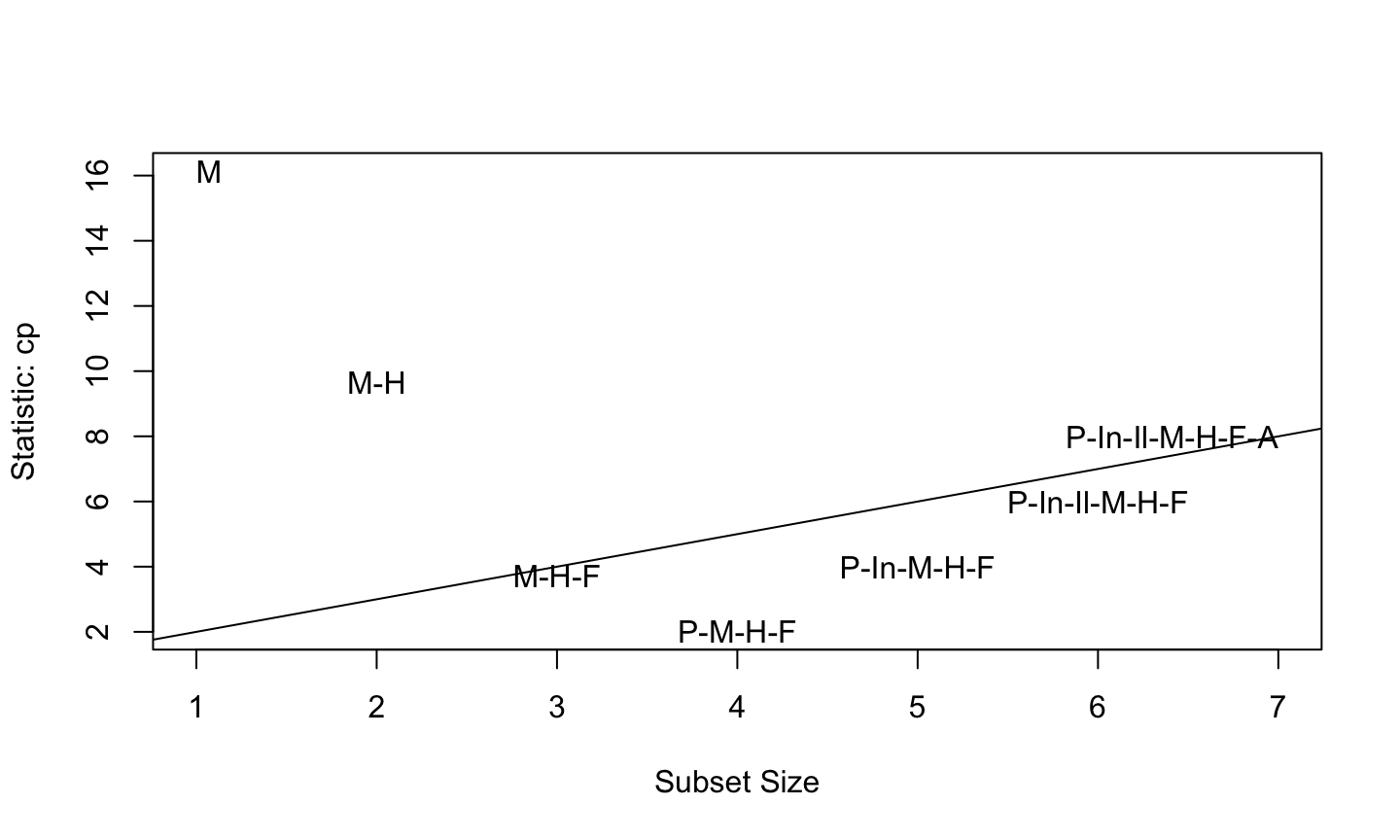
The smaller model is preferred (since it has smaller RMSE) using leave-one-out crossvalidation.
modele = train(f2, data = statedata, trControl = cv_loo,
method = "lm")
modelf = train(f3, data = statedata, trControl = cv_loo,
method = "lm")
print(modele$results)
## intercept RMSE Rsquared MAE
## 1 TRUE 0.770042 0.6657615 0.6377097
print(modelf$results)
## intercept RMSE Rsquared MAE
## 1 TRUE 0.7898955 0.6479315 0.6639939